AMD の Marek Olšák 氏より、オープンソースで開発される AMD GPU 向け OpenGLドライバー RadeonSI に、CDNA 2 アーキテクチャ を採用するとされる Aldebran GPU のサポートを追加するパッチが投稿された。
Aldebaran はグラフィクス機能を持たないコンピュート専用 GPU だが、マルチメディアエンジンを搭載する関係でサポートが RadeonSI にも追加される。
それは Arcturus/MI100 でも同様で、マルチメディアエンジンの用途には機械学習におけるオブジェクト検出等が想定されている。
Linux Kernel に 「Aldebaran」 GPU をサポートするパッチが投稿される ―― CDNA 2/MI200 のコードネーム? | Coelacanth’s Dream
Index
Aldebaran は gfx90a
パッチが投稿されたタイミングや内容から、Aldebaran 、MI200 の GPUID は gfx90a ではないかと考えられたが、今回投稿されたパッチからそれが確定した。
GPUID gfx90a では、LLVM に投稿されたパッチの内容から、FullRateFP64Ops 、PackedFP32Ops をサポートすることが分かっており、演算ユニットが大幅に強化されていることが予想できる。
また、Workgroup を分割し、異なる CU でそれぞれ実行することを可能とする TgSplit モードのサポートも追加されている。
LLVM に GFX90A のサポートが追加される ―― CDNA 2/MI200 か | Coelacanth’s Dream
return "gfx909"; case CHIP_ARCTURUS: return "gfx908"; case CHIP_ALDEBARAN: return "gfx90a"; case CHIP_NAVI10: return "gfx1010"; case CHIP_NAVI12:
命令のプリフェッチ機能が強化
Aldebaran では命令のプリフェッチ (先読み) 機能が、 RDNA アーキテクチャ よりも離れた命令を読み込めるよう強化されている。
unsigned prefetch_distance = 0; if (!i.info->has_graphics && i.info->family >= CHIP_ALDEBARAN) prefetch_distance = 16; else if (i.info->chip_class >= GFX10) prefetch_distance = 3; if (prefetch_distance) binary->rx_size = align(binary->rx_size + prefetch_distance * 64, 64);
ここでの命令のプリフェッチ機能は RDNA/GFX10 から追加された機能であり、RDNA/GFX10 では命令を、現在の PC (Program Counter)1 から最大 3個のキャッシュライン分 (各 64 Bytes) プリフェッチすることができる。
それが Aldebaran では最大 16個のキャッシュライン分プリフェッチできるよう強化されている。
命令のプリフェッチがうまく働ければ、命令のロードを短縮することができ、演算速度の向上に繋がる。
ここでのキャッシュラインサイズは CU ごとに持つ L1命令キャッシュのことを示しているものと思われ、サイズは GCN アーキテクチャ 、RDNA アーキテクチャ ともに 64 Bytes となっている。
この機能は CDNA 1 アーキテクチャ 、 Arcturus/MI100 ではサポートされていなかったため、CDNA 系では CDNA 2 アーキテクチャ から追加された機能と言え、RDNA/2 アーキテクチャ とのプリフェッチの規模の違いはそれぞれの特徴を表しているとも言える。
Alderbaran で RDNA/2 よりも強化した理由については、TgSplit モードと同様に、FullRate64Ops の対応によって規模が大きくなった演算部の使用率/稼働率を高める目的があるのではないかと思われる。
L2キャッシュのラインサイズが 128 Bytes に
if (!info->has_graphics && info->family >= CHIP_ALDEBARAN) info->tcc_cache_line_size = 128; else info->tcc_cache_line_size = 64;
これまでの GCN アーキテクチャ と Arcturus/MI100 では L2キャッシュのキャッシュラインサイズは基本 64 Bytes だったが、Aldebaran では 128 Bytes となる。
上の引用部では見切れてしまっているが (含めようとすると今回のパッチで削除された部分も入ってしまう)、RDNA アーキテクチャ では RDNA/GFX10 からキャッシュラインサイズは 128 Bytes となっており、命令のプリフェッチ機能のように、 CDNA 2 アーキテクチャ が RDNA アーキテクチャ から取り込んだ部分と言えなくもない。
単に開発時期の違いから RDNA が先に採り入れていた、というだけのこととも考えられるが。
キャッシュラインサイズはメモリにアクセスするデータの単位を表し、ラインサイズを増やすことは 1度にアクセスするメモリのデータ量を増やすことを意味する。
RDNA アーキテクチャ の資料では 128 Bytes に増やした利点について、少ないメモリリクエストで広い帯域を活用できる、と説明していた。2 Aldebaran も同様の効果を狙って増やしたものと考えられる。
また、キャッシュラインに付けられたメモリアドレスを記録するタグに対するサイズが増え、より効率的にデータ部にキャッシュメモリを使うことができる。
それと TCC は Texture Channel Cache の略とされ、L2キャッシュの意。
割り当て可能なベクタレジスタの個数が倍に?
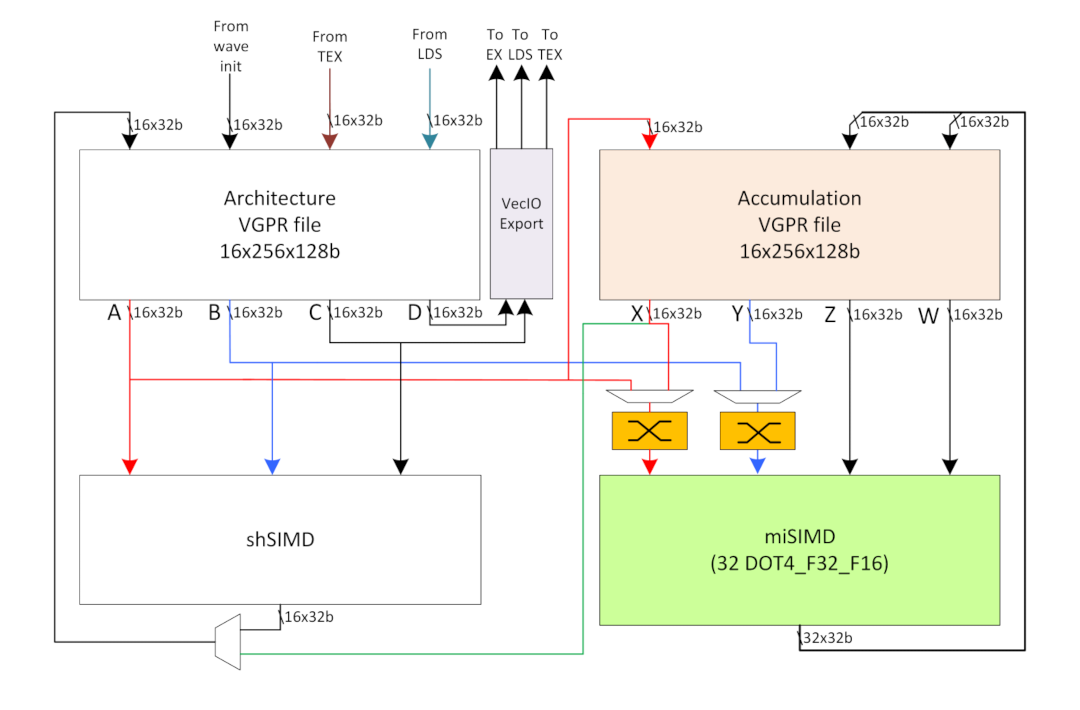
また、Aldebaran ではスレッドあたりに割り当て可能な VGPR/ベクタレジスタの数が 512個となった。
if (!info->has_graphics && info->family >= CHIP_ALDEBARAN) { info->min_wave64_vgpr_alloc = 8; info->max_vgpr_alloc = 512; info->wave64_vgpr_alloc_granularity = 8; } else { info->min_wave64_vgpr_alloc = 4; info->max_vgpr_alloc = 256; info->wave64_vgpr_alloc_granularity = 4; }
これは LLVM の記述と合わせて、 Arcturus/MI100 ではドット積の演算を主に処理する miSIMDユニット側からのみ扱えた AccVGPR を、通常の SIMDユニット shSIMD (shader SIMD) からも扱えるよう変更したのではないかと考えられる。
shSIMD から扱えるベクタレジスタ数が増えることで、通常の処理において、レジスタから追い出されること (再割り当て) の頻度を減らすことができる。
上 2つは RDNA アーキテクチャ から採り入れたようにも見える機能だったが、この改良については CDNA アーキテクチャ から続くものだろう。
SQ_MAX_PGM_VGPRS = 512, // Maximum programmable VGPRs across all targets. AGPR_OFFSET = 226, // Maximum programmable ArchVGPRs across all targets.
-
(PC, Program Counter: 次に実行する命令のアドレスを格納しているレジスタ) ↩︎
-
AMD PowerPoint- White Template - RDNA_Architecture_public.pdf ↩︎