Mesa3Dに、RADV(Vulkan) ドライバーの ACOバックエンド においても NGG(Next Generation Geometry) をサポート、そしてデフォルトで有効にするマージリクエストが投稿された。
aco: Implement NGG GS (!6964) · Merge Requests · Mesa / mesa · GitLab
ここで一度、NGG について整理も兼ねて解説を試みてみる。
Index
NGG (Next Generation Geometry)
とは言っても、NGG と各シェーダーステージの関係は、ACOバックエンド のドキュメントに非常に分かりやすくまとめられている。
src/amd/compiler/README.md · master · Mesa / mesa · GitLab
ただ、ドキュメントとこの記事で解説される内容が NGG の全てではないことを留意して頂きたい。
ややこしくて複雑なシェーダーステージ
まず、ソフトウェア側で定義されているシェーダーステージの中で、オブジェクトの頂点処理を行なうバーテックスシェーダー(Vertex Shader, VS)、頂点の増減を行なうジオメトリシェーダー(Geometry Shader, GS)、そしてピクセル処理を行なうピクセルシェーダー(Pixel Shader, PS) を GPU で実行する時、VS → GS → PS という順番で実行される。
そして PS を実行する時、ハードウェア側では VSステージでのみ書き込めるバッファを PSステージで受け取るのだが、GS が間に入るとこれがスムーズにいかなくなる。
GS の処理結果は一度 VRAM に出力され、PS が受け取るバッファには書き込まれない。
そのため、ハードウェア側の VSステージで GS の処理結果を VRAM から読み込み、それを PS へのバッファに書き込む手間が必要となる。
RadeonSI(OpenGL)/RADV(Vulkan) ドライバーではこれを GS copy シェーダー と呼んでいる。
ハードウェアから見れば、この GS copy は VSステージで実行されるが、ソフトウェアから見れば従来のグラフィクスパイプラインから外れたものであり、ドキュメントではうまいこと処理するため糊付けされたコード部としている。
ややこしいのは、ソフトウェア側とハードウェア側とで定義されているシェーダーステージが異なり、どちらにも Vertex Shaderステージがあるが、ハードウェア側の VSステージで常にソフトウェアの VS が処理される訳ではないことだ。
手間を解消する NGG
そして、NGG というのはハードウェア側に新設されたシェーダーステージであり、従来のの GS と VS を統合させたものである。
これによって GS copy の手間が必要なくなり、直接 PSステージへのバッファに処理結果を書き込めるようになる。
Vega /GFX9 世代と NGG を使わない場合の RDNA /GFX10 世代でのグラフィクスパイプラインにおいても、一部ハードウェア側のシェーダーステージの統合が行なわれているが、VRAM に処理結果を書き込むステージがあり、まだ GS copy が必要とされている。
NGG の利点の 1つとして、GS copy が必要なくなったことによる VRAM へのトラフィック減少、それとジオメトリシェーダーが間に入ってもバッファに書き込めることによる処理の高速化が期待できる。
また、NGGステージでは テッセレーション評価シェーダー(Direct3Dにおけるドメインシェーダー) も実行される。
NVIDIA が Turing 世代で新設したプログラムシェーダー、Mesh Shader も近い仕組みとなっており、ACOバックエンド を開発する Valve の Timur Kristóf 氏は XDC2020 での発表の中で、NGGステージで Mesh Shader も実行可能ではないかと述べている。1
NGG をサポートする GPU
NGG は RDNA /GFX10 世代の AMD GPU からサポートされているが、全てではない。
RX 5500 XT 等のベースとなる GPU ASIC、Navi14 はハードウェア側にバグがあるらしく2、NGG を有効にすることはできず、GS copy を使用するグラフィクスパイプラインでシェーダーを実行する。
Navi12 も NGG をサポートしているはずだが、Navi12 をベースとした製品は MacBookPro向けの Radeon Pro 5600M しか出ていないため、現状で一般的に NGG を使えるのは Navi10 をベースとする RX 5700 /XT 等だけとなる。
RDNA 2 /GFX10.3 世代の GPU を持つ VanGogh APU も、NGG が使用可能かの判定部に、専用VRAMを持っている GPU のみ、というコードが追加されているため、現状では NGG を使用不可とされている。
NGG によって VRAM のトラフィックを従来より減らせるはずであり、メモリの帯域不足に悩ませられる APU でもサポートして欲しいところだ。
おまけ RDNAアーキテクチャおける LDS のモード
書いたはいいけど置き場所に困ったため、とりあえずおまけとしておく。AMD GPU における CU(Compute Unit) はメモリキャッシュとは別に、明示的に指定して使用するローカルメモリ、LDS(Local Data Share) を持つ。
LDS には広帯域低レイテンシでアクセスすることができ、これを活用することが GPU の性能を引き出す上で重要となる。
LDS は GCNアーキテクチャ では CU あたり 64KB(32バンク) となっており、RDNAアーキテクチャ でもそれは変わらないが、CU 2基をまとめた WGP(Work Group Processor)/Dual CU がプロセッサの最小単位となり、WGP全体では 128KB(64バンク) の LDS を持つ。
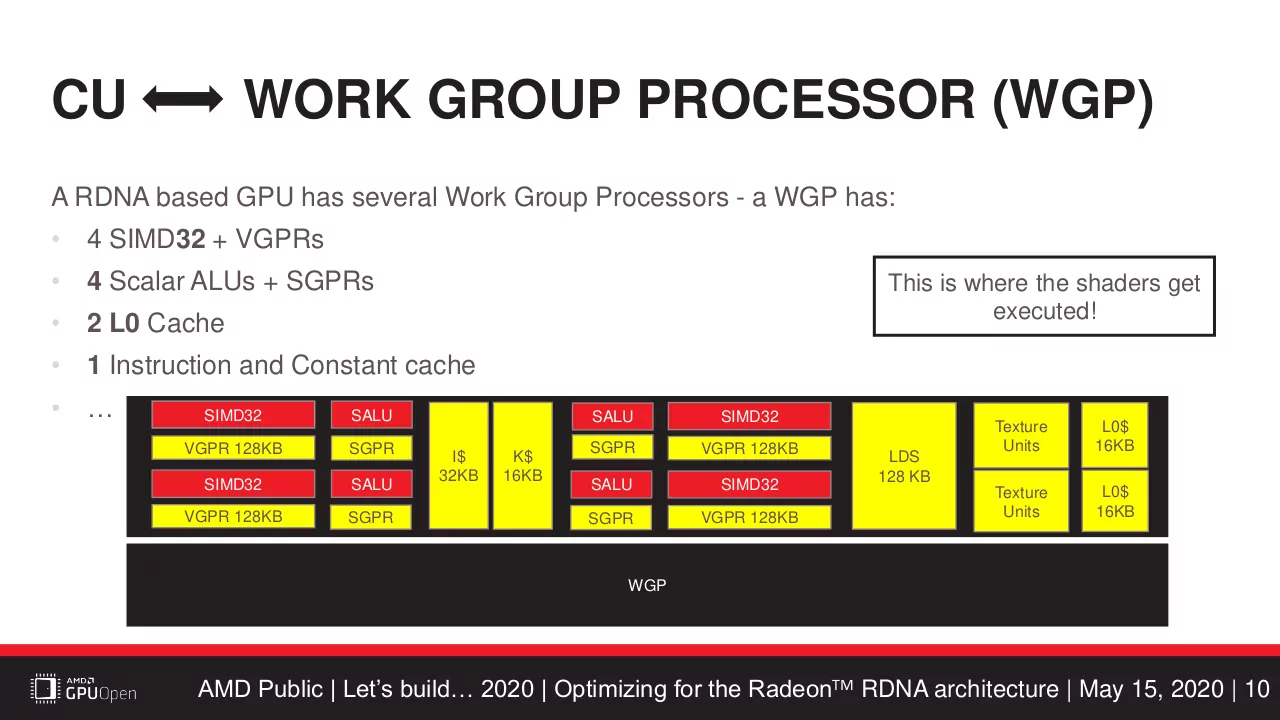
RDNA WGP (Work Group Processor)
しかし、LDS 128KB(64バンク) 全てをフラットに使える訳ではなく、実際には下記の図のように、RDNAアーキテクチャ でも GCNアーキテクチャ 同様、CU 2基それぞれが LDS 64KB(32バンク) を持ち、それらがクロスバー接続されるという形になっている。
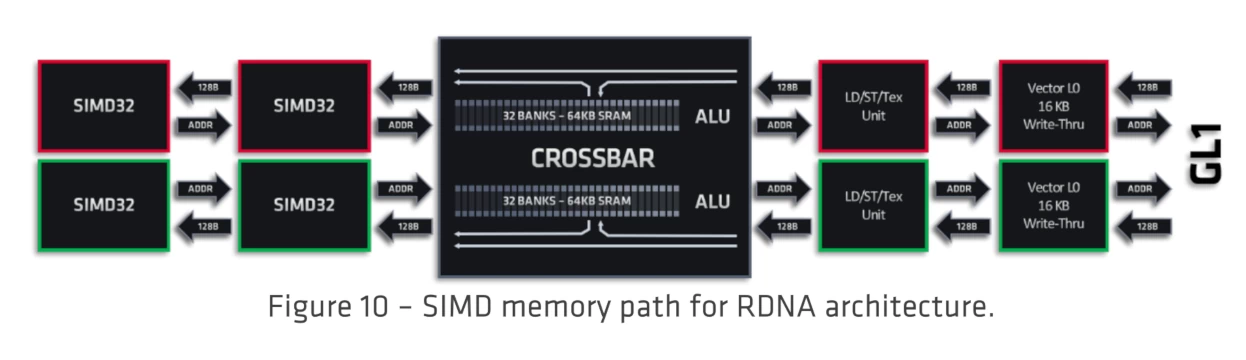
Dual Compute Units memories
画像出典: https://www.amd.com/system/files/documents/rdna-whitepaper.pdf (Page14)
RDNAアーキテクチャ には LDS の割り当てにおいて 2つのモードがあり、AMD は CU Mode 、WGP Mode としている。3
CU Mode では、L0キャッシュ、テクスチャユニットを共有する 2基の SIMD32ユニット、ざっくりと言えば WGP の片方の CU 側の LDS 64KB(32バンク) のみが割り当てられる。
WGP Mode では、WGP 1基(CU 2基、SIMD32 4基) に LDS 128KB(64バンク) が割り当てられ、CU Mode より広いローカルメモリを扱うことができる。
しかし、上述したように、LDS 64KB(32バンク) 2基がクロスバー接続されているという形であるため、ある SIMD32ユニットから見た時、近い LDS と遠い LDS が存在することになる。そして、遠い LDS の帯域は近い LDS より劣る。
これにより、WGP Mode では LDS 全体の帯域が下がり、性能が低下する場合がある。
CU Mode では近い LDS のみを割り当てるため、扱えるローカルメモリの範囲は狭まるが、常に WGP Mode よりも高い帯域でアクセスできる。
だが WGP Mode にも、LDS を共有する単位少なくとも 4-Wave と記されている
において、多くの SIMD32ユニットを扱え、テクスチャメモリへの帯域幅を増やせるという利点がある。
性能の最適化において、2つのモードのどちらを選択するかが関わってくると思われるが、RadeonSI/RADV ドライバー ではどうしているのかは不明。
(追記)RadeonSI/RADV ドライバーでは WGP Mode を採用していた。
src/amd/common/ac_gpu_info.c · 3c2489d2e45b3013361c7284ed9de14fe40554cc · Mesa / mesa · GitLab
RDNAアーキテクチャ はスレッドをまとめた Wave という単位において、ネイティブでは 32スレッド(Wave32) とし、GCNアーキテクチャ と同じスレッド数である 64スレッド(Wave64) にも対応する。
CU Mode 、WGP Mode ということから混同してしまいがちだが、これら Wave は、LDS の割り当てにおける 2つのモードとはまた別であるようだ。
また、同じスレッド数とは言うものの、RDNAアーキテクチャ では Wave64 を 2つの Wave32 に分解して発行されるため、GCNアーキテクチャ 同様に実行される訳ではないとされている。
RadeonSI ドライバーでは RDNA GPU も Wave64モードで各シェーダーを実行するように | Coelacanth’s Dream
参考リンク
- Optimizing for the Radeon RDNA architecture - GPUOpen_Let’sBuild2020_Optimizing for the Radeon RDNA Architecture.pdf
- https://www.amd.com/system/files/documents/rdna-whitepaper.pdf
- RDNA_Shader_ISA.pdf
- 西川善司の3DGE:新設の「プリミティブシェーダ」を搭載し,Radeon RX Vegaはどこへ行く?
- 西川善司の3DGE:GeForce RTX 20完全理解。レイトレ以外の部分も強化が入ったTuringアーキテクチャにとことん迫る
-
【XDC2020】 ACOバックエンドの今後の計画 ―― RDNA 2, RT, Mesh Shader | Coelacanth’s Dream ↩︎
-
radv/gfx10: do not use NGG with NAVI14 (a4e6e59d) · Commits · Mesa / mesa · GitLab
radv/gfx10: enable all CUs if NGG is never used (53b50be3) · Commits · Mesa / mesa · GitLab
src/amd/vulkan/radv_device.c · 6f3352b6a7648e50f19edffe056d25211375b247 · Mesa / mesa · GitLab ↩︎ -
RDNA_Shader_ISA.pdf (Page18, 91) ↩︎