オープンソースで開発される AMD GPU向け OpenGLドライバー RadeonSI への最新コミットの中で、ネイティブで Wave32モードに対応する RDNA /Navi1x GPU も Wave64モードで各シェーダーを実行するように変更が行なわれた。
Wave は コンピュートユニット(CU) 内の SIMDユニットが実行するスレッドの塊を意味し、後の数字はスレッドの数を意味する。Wavefront とも呼ぶ。
Index
GCN と RDNA の両アーキテクチャにおける Wave の違い
GCN アーキテクチャ では CU あたりに SIMD16ユニットを 4基持ち、各SIMD16ユニットが 64スレッド(Wave64) を 4サイクル掛けて命令を発行、処理する方式を取る。
対して、RDNA アーキテクチャ では CU あたりに SIMD32ユニットを 2基持ち、各SIMD32ユニットが 32スレッド(Wave32) を 1サイクルで命令を発行、処理する方式となる。
RDNA アーキテクチャ は Wave64 での実行モードにも対応し、その場合 GCN アーキテクチャ の方式とは異なり、2つの Wave32 として実行する。
GCN アーキテクチャ では命令の発行に 4サイクル掛かるが、RDNA アーキテクチャ は 1サイクルと短いレイテンシで処理できるため、グラフィクス処理やゲーミング向けとして有利である……とされていたが、今回の RadeonSI に加えられた変更は、RDNA /Navi1x GPU でもネイティブの Wave32 ではなく Wave64 でシェーダー実行するというものだ。
Wave64 で実行する理由
以前より、通常 Pixel Shader は Wave64、Vertex/Tess/Geometry Shader は Wave32 で実行するようにしていたのを、後者も Wave64 で実行するようにしたのが今回の変更点となる。
また、RDNA_Architecture_public.pdf には Compute Shader は Wave32 とあるが、何か問題が発生するらしく、RadeonSI では Wave64 となっている。
Vertex/Tess/Geometry Shader も Wave64 で実行する方が良いと考える理由に、GPUドライバーの開発者である Marek Olšák 氏は以下の項目をあげている。
- greater chance of L0 cache hits, because more threads are assigned to the same CU
- scalar instructions are only executed once for 64 threads instead of twice
- VGPR allocation granularity is half of Wave32, so 1 Wave64 can sometimes use fewer VGPRs than 2 Wave32
- TessMark X64 with NGG culling is faster with Wave64
ざっくりとした意訳
- 多くのスレッドが同じ CU で実行されるため、L0キャッシュにヒットする確率が高まる
- スカラ命令は 64スレッドあたり 2回ではなく、1回だけしか実行できない
- Wave64 の場合に割り当てられるベクタレジスタ(VGPR) の粒度は Wave32 の半分であるため、1 Wave64 が使用するベクタレジスタの量は 2 Wave32 よりも少なくなることがある
- NGGカリングを有効にして TessMark X64 を実行した時、Wave64 の方が速い
考察的な
一部詳細を補完しつつ、Wave64 の方が性能が良い理由を考えていきたい。
まず L0キャッシュとは RDNA アーキテクチャ の CU がそれぞれ持つもので、容量は 16KB となっている。
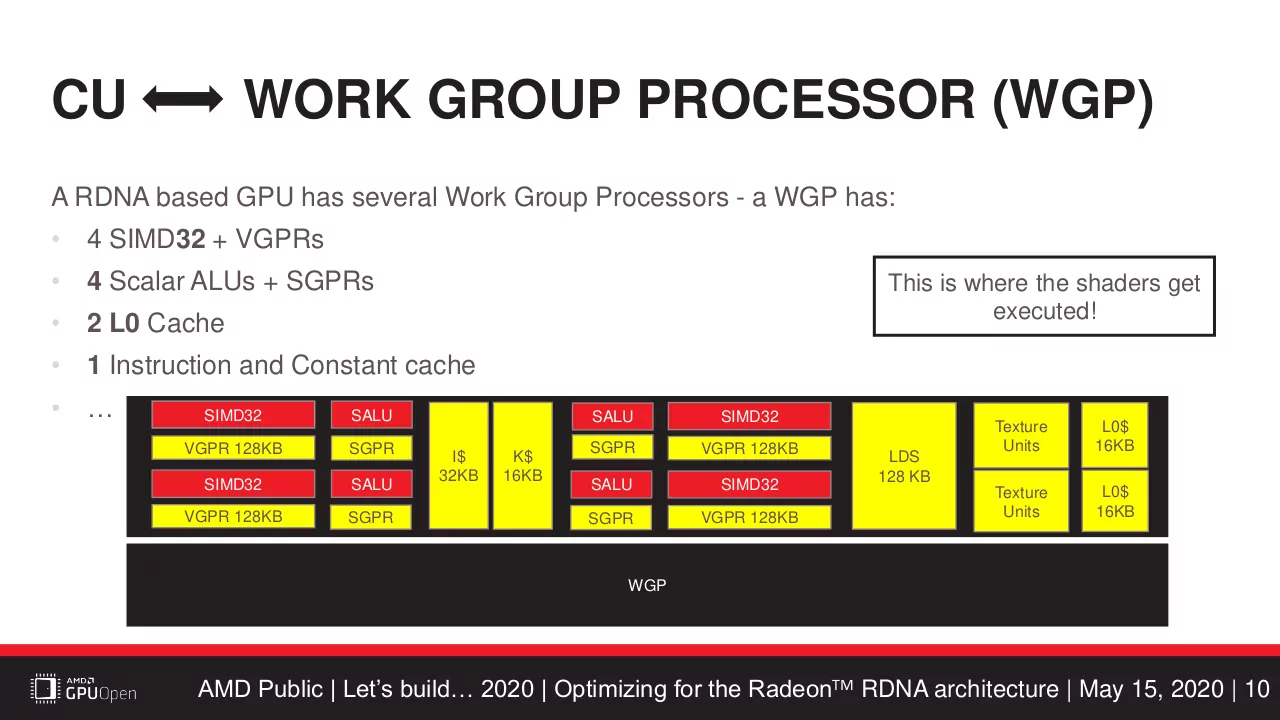
RDNA WGP (Work Group Processor)
WGP は 2CU をまとめた形となり、L0キャッシュを 2基持つが、同WGPであってもキャッシュコヒーレントは取られない。
そのため、多くのスレッドを同じ CU で実行すれば、L0キャッシュにヒットする確率は高くなるというのは合っているが、2つの Wave32 を実行するのと、Wave64 を 2つの Wave32 として実行するのとでスレッド数が変わらないように思う。
しかし Wave64モードにキャッシュを効果的に使える要素はあり、それは 3つ目とも関係する。
RDNA は Wave64 を 2つの Wave32 として処理する時、ベクタレジスタは 2つの Wave32 で共有する。そのために割り当てられるベクタレジスタの粒度は Wave32 時の半分となる。
そして RDNA では、2つの Wave32 を順番に実行するのではなく、命令をある程度まとめ、それぞれの命令を low と high に半分ずつに分解、最初に low 群を処理し、その後 high 群を処理する Sub-Vector Mode がソフトウェア制御で実装されている。

RDNA Sub-Vector Mode
SIMDユニットの使用率は変わらないが、low の命令群を処理し終わった時点でベクタレジスタの半分を解放することができ、キャッシュをより効果的に使用できるとしている。
Sub-Vector Mode でのメモリ効率の良さが、Wave64 時の性能向上に繋がっているのだろう。
4つ目は結果的なものであるが、同様にメモリ効率の良さから来るものではないかと思う。
ただ、3つ目は正直に言うとよくわからない。
上記画像を見てわかるように、RDNA は CU内にスカラユニット(SALU) を SIMDユニットと同数備えるため、Wave64 を 2つの Wave32 として実行するなら、スカラ命令も 2回発行できていいように思うが、実際は Wave64(64スレッド) に対して 1回だけとなる。
スカラユニットは条件分岐や割り込み、アドレス計算等の制御処理を担当し、その点では前世代の GCN と変わらない。
ベクタでは 2つの Wave32 に分けて実行するが、制御は Wave あたりで行なわれるため、スカラ命令は 1回だけ、ということなのかもしれないが、それ自体がどのように効果的までかは自分の頭が及ばない。
シェーダーの実行に細かい制御はそこまで必要でないとか?
終わりに、RDNA アーキテクチャ は Wave32 と Wave64 のどちらにも対応し、それぞれに利点がある。処理によってどちらが優れているかは検証を重ねる必要がある。よって、今回のようなチューニングがこれからも続けられると思われる。
これは、RDNA アーキテクチャ には柔軟性があり、それだけ性能を引き出す余地があると言える。
今後のさらなる RDNA GPU に向けた最適化に期待したい。
そして、その様子をオープンソースであることにより追えるのは、自分のようなオタクにとってありがたい話だ。
参考リンク
- Optimizing for the Radeon RDNA architecture - GPUOpen_Let’sBuild2020_Optimizing for the Radeon RDNA Architecture.pdf
- 7nm “Navi” GPU
- RDNA_Architecture_public.pdf
- Introduction - rdna-whitepaper.pdf
- AMDのRDNAアーキテクチャの「Navi GPU」を読み解く - Hot Chips 31 | マイナビニュース
- コンピュータアーキテクチャの話(366) GCNのスカラユニットとベクトル演算 | マイナビニュース