オープンソースで開発され、LLVM をベースとする Intel GPU の OpenCLコンパイラ intel-graphics-compiler に Xe-HP サポートへ向けたパッチが投稿され、メインラインに取り込まれてきている。
Index
DPAS, Long パイプラインが追加 ―― FPも?
以前、オープンソースで開発される Intel GPU のシェーダーコンパイラバックエンドに投稿された Xe-HP の ISA (Instruction Set Architecture) をサポートするパッチで語られたように、Xe-HP EU では 2つのパイプラインが追加される。
2つの非同期パイプラインが追加される Xe-HP EU | Coelacanth’s Dream
前回は追加された 2つのパイプラインと演算命令を発行する Issue Port の構成について、1つは INT/FP 両方を実行していたものを分割し、もう 1つは FP64 (DP) を実行するものではないかと推測したが、
今回 intel-graphics-compiler に取り込まれたパッチの内容によれば、1つは dpas (Dot Product Accumulate Systolic) 命令を実行するためのもので、もう 1つは FP64 に加え Int64 もサポートする Long (64-bit) パイプラインだとされる。
Xe-LP EU では INT/FP 演算命令を同一のパイプラインで実行していたが、Xe-HP EU では Int64/FP64 データタイプの演算を実行する Longパイプラインが追加されたことで INT/FP をそれぞれ独立して実行できるようになると考えられる。
パイプライン、Issue Port が増設されれば、それだけ命令の発行、実行数を増やすことができ、ピーク IPC は向上する。
コントロールフローに関しても Xe-HP EU では変更が入っており、Xe-LP では分岐を実行する Control Flowパイプラインが実装されているが、Xe-HP では INTパイプラインに統合されている。
ただ、Xe-HP は 512EU, 1300MHz で clpeak を FP32 での演算を実行するデモで 約 10.6 TFLOPS という結果を出しており、Longパイプラインを FPパイプラインとして実行するのではでは 約 5.3 TFLOPS となり、デモの結果と一致しない。(SIMD幅が Xe-LP と同じ 8-wide だという前提だが)
Intel Architecture Day 2020 個人的まとめ ―― XeHP は 1-Tile 512EU、XeLPアーキテクチャ詳細 | Coelacanth’s Dream
自分でもここを書いていて気付いたが、Xe-HP では Control Flowパイプラインが無くなり、INTパイプラインに統合されている。そのため FPパイプラインを追加しても、Xe-LP から追加されるパイプラインは実質 2個となる。それならば FP32 演算を 2つのパイプラインで実行できるため、説明らしい説明が付く。
本来なら文章を再構成すべきなのだろうが、メモとしてとりあえずこのままにしておく。
| Xe EU | Issue Port 0 | IP 1 | IP 2 | IP 3 | IP 4? | ||
|---|---|---|---|---|---|---|---|
| Xe-LP | Branch (Control Flow) |
Send | Short (INT /FP) |
Math | - | - | - |
| Xe-HP | Send | INT? (int8/16/32) /Branch? |
Math? | DPAS? | Long? (Int64 /FP64) |
FP? (FP16/32, BF16) |
|
| In-Order | Out-of-Order | In-Order | Out-of-Order | Out-of-Order | In-Order | In-Order |
EU あたりのスレッド数とレジスタファイルが増加
パッチでは Xe-HP EU で EU あたりのスレッド数とレジスタファイルが増量されたことが示唆されている。
画像は GDC 2019 で公開された 「The Architecture of 11th Generation Intel® Processor Graphics」のスライドで内容は Gen11アーキテクチャについてではあるが、比較的最近の Intel GPU アーキテクチャを Intel 自らが仔細に解説したとても参考になる資料であるため引用させていただいた。
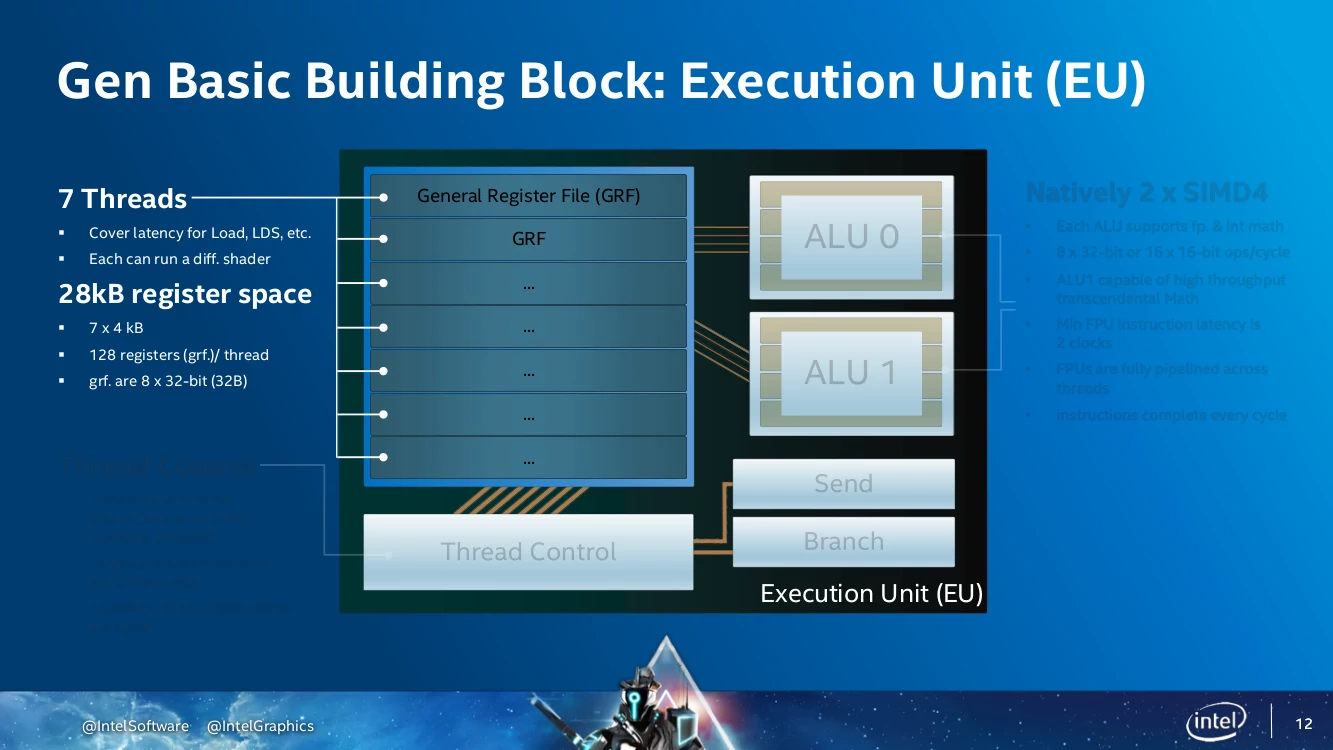
Gen11: Gen Basic Building Block: Execution Unit (EU)
画像出典: GDC 2019 Tech Sessions
従来の Intel GPUアーキテクチャでは、EU あたり 7スレッド、スレッドあたりのレジスタファイルは 128エントリ (4KiB) となっており、この点は Xe-LP でも同様と思われる。
それが以下引用部を読み取るに、Xe-HP では EU あたり 8スレッドとなり、その時のスレッドあたりのレジスタファイルに変更は無いため、1スレッド分が増設されたと考えられる。
さらには 4スレッドに設定することも可能になっており、その場合スレッドあたりのレジスタファイル数は倍の 256エントリ (8KiB) になる。
// Set number of threads if it was not defined before if (numThreads == 0) { if (overrideNumThreads > 0) { numThreads = overrideNumThreads; } else { switch (platform) { case GENX_XE_HP: switch (numRegTotal) { case 256: numThreads = 4; break; default: numThreads = 8; } break; default: numThreads = 7; } } }else if (overrideNumThreads > 0) { switch (platform) { case GENX_XE_HP: switch (overrideNumThreads) { case 4: numRegTotal = 256; break; default: numRegTotal = 128; } break; default: numRegTotal = 128; }
使えるレジスタファイルが増えれば、レジスタ溢れが発生しキャッシュ、メモリに退避し、復元する手間を減らせるため、処理によっては性能が 8スレッド時よりも向上することが考えられる。
Xe-HP では推論処理に活用される DP4A 命令等、ソースオペランドが 3個となる命令に対応しているため、機械学習、推論では 4スレッドモードが 8スレッドモードよりも有利となるかもしれない。
また行列演算では入力値の多くを再利用するため、レジスタファイルを活用しやすい。キャッシュ、メモリへのアクセス数が減らせれば、演算性能と電力効率を高めることができる。