オープンソースで開発される Intel GPU のシェーダーコンパイラバックエンドに、Xe-HP GPU の ISA (Instruction Set Architecture) をサポートするパッチ (マージリクエスト) が投稿された。
偶然だが、そのマージリクエストが Mesa3D の Gitlabレポジトリにおける 1000個目のマージリクエストであり、次世代の Intel GPU をサポートするパッチは記念としてぴったりと言えるかもしれない。
Xe-HP は、Xe-LP から対応していた DP4A 命令に加え、BFloat16フォーマットや倍精度演算 (DP) に対応した機械学習に最適化されたアーキテクチャである。
Xe-LP から拡張される Xe-HP EU
パッチを投稿した Intel の Francisco Jerez 氏によるコメントでは、Xe-HP EU は複数の非同期ALUパイプラインを持ち、
それら複数のパイプラインは、既存の FPUパイプライン Tiger Lake, Rocket Lake, Alder Lake, DG1 などに採用されている Xe-LP EU のことを指していると思われる
から複数の非同期パイプラインに分割したとも説明している。
パイプラインは浮動小数点 (FP)、整数 (Int)、倍精度浮動小数点 (DP) に分けられる。
また、パイプライン間のデータ依存関係についてはコンパイラ側で制御、管理するとし、そのためのパッチも含まれている。
This MR implements compiler support for the ISA of the Intel XeHP family of GPUs. The most invasive compiler changes relative to previous generations are the result of the preexisting FPU pipeline being split into multiple asynchronous pipelines (a floating-point, integer and long AKA double-precision pipeline), which is highly visible to software because the hardware is not able to guarantee data coherency across instructions (already since TGL), so the compiler is now responsible for keeping track of which pipeline will be executing which instruction and specifying synchronization primitives in order to resolve any cross-pipeline dependencies.
The execution units of XeHP platforms have multiple asynchronous ALU pipelines instead of (as far as software is concerned) the single in-order pipeline that handled most ALU instructions except for extended math in the original Xe. It's now the compiler's responsibility to identify cross-pipeline dependencies and insert synchronization annotations whenever necessary, which are encoded as some additional bits of the SWSB instruction field.
Xe-LP EU (Execution Unit) は以下のように、命令を発行する Issue Port 0 は FP/INT演算器を、Port 1 は三角関数等の超越関数を実行する EM (Extended Math)演算器を担当する構成となっている。
Francisco Jerez 氏のコメントと合わせれば、 Xe-LP EU では、EM演算器で処理される演算命令を除いて、FP/INT が同一のパイプラインでインオーダー方式に処理するアーキテクチャだったと説明できる。
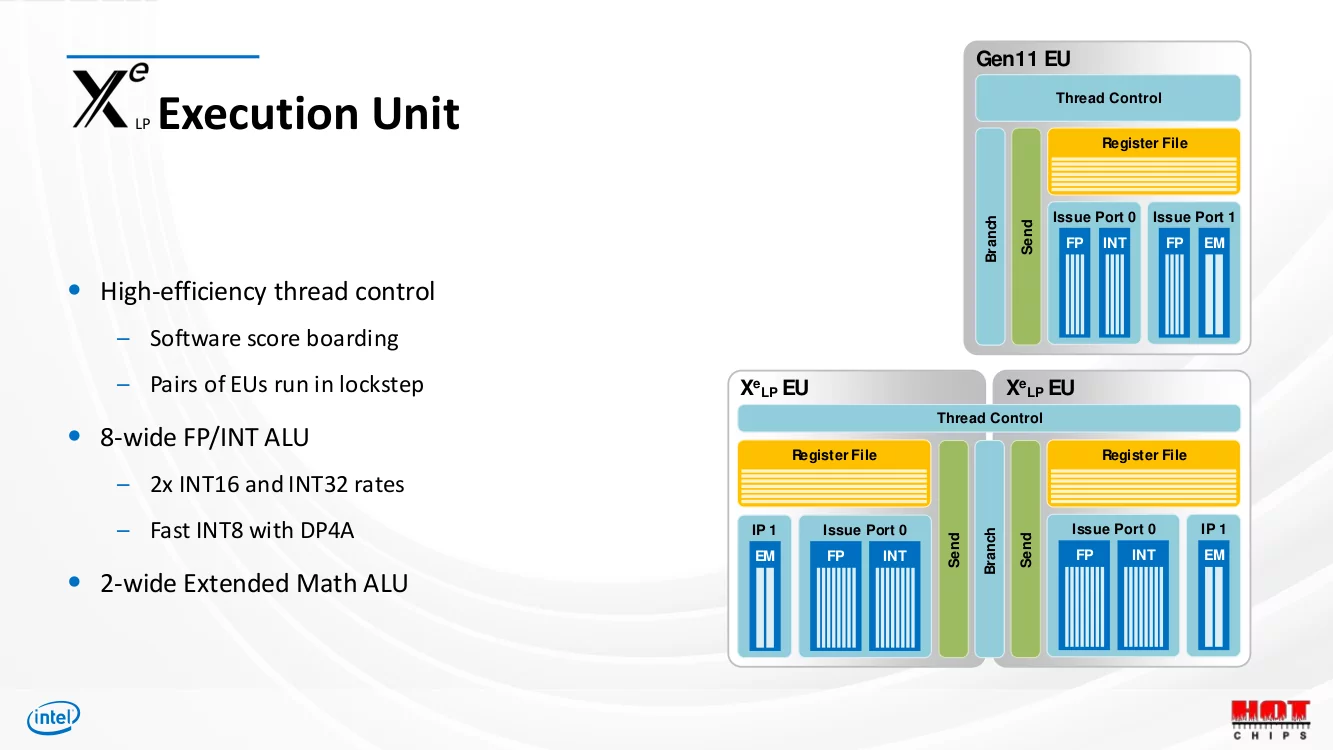
Xe-LP Execution Unit
コード内のコメントでは、(Xe-LP から) 2つの非同期ALUパイプラインが追加されているとしており、上述の説明と合わせるに、Xe-LP では FP/INT演算器に接続されていた Issue Port 0 を分割、それぞれに独立した Issue Port を搭載し、そして倍精度演算器と一緒に Issue Port をもう 1基搭載したのが Xe-HP EU の構成ではないかと考えられる。
Issue Port が増えればその分多く演算命令を発行でき、多くの処理を行うことができる。また非同期に演算処理を行うことも可能になる。
こうしたアーキテクチャの変更は、FP32 と INT32 の演算器を並列に動作できるにした NVIDIA Turing GPU のそれと近いように思える。1
コンパイラ側で制御する必要はあるが、パッチの日付は 1,2年前のものとなっており、だいぶ以前から取り組んでいたことが窺える。Xe-HP について内部で開発していたものを、サポートのためオープンにする段階に来たとも言える。
Xe-HP の特徴として以前より IPC の向上がアピールされていたが、そのためのアーキテクチャ改良の 1つが Issue Port の分割、増設なのだろう。2
/** * TGL+ SWSB RegDist synchronization pipeline. * * On TGL all instructions that use the RegDist synchronization mechanism are * considered to be executed as a single in-order pipeline, therefore only the * TGL_PIPE_FLOAT pipeline is applicable. On XeHP+ platforms there are two * additional asynchronous ALU pipelines (which still execute instructions * in-order and use the RegDist synchronization mechanism). TGL_PIPE_NONE * doesn't provide any RegDist pipeline synchronization information and allows * the hardware to infer the pipeline based on the source types of the * instruction. TGL_PIPE_ALL can be used when synchronization with all ALU * pipelines is intended. */
| Xe EU | IP 0 | IP 1 | IP 2 | IP 3 |
|---|---|---|---|---|
| Xe-LP | FP/INT | EM | - | - |
| Xe-HP | INT? (or FP?) |
EM | FP? (or INT?) |
DP? |
Xe-HP は、タイルと呼ぶ GPUチップを、パッケージ上に単体もしくは複数 (2, 4) 搭載する構成を取り、1タイルあたりに EU を 512基搭載している。
Intel Architecture Day 2020 で披露されたデモでは、1タイル (512EU) 構成の Xe-HP が 1300MHz で動作し、約10.6 TFLOPs というピークFP32演算性能を達成していた。
Xe-LP の同様の 8-wide FPパイプライン 1ポートという構成では、ピークFP32演算性能は約5.3TFLOPs と一致しなかったが、Xe-HP で増設された倍精度演算器のパイプラインも単精度演算器として活用していたとすると約10.6TFLOPsというデモの性能と近い数字が出る。
パイプラインあたりの演算幅を増やした可能性もあるが、今回のパッチで明かされた情報と合わせて上のような推測もできる。
Intel Architecture Day 2020 個人的まとめ ―― XeHP は 1-Tile 512EU、XeLPアーキテクチャ詳細 | Coelacanth’s Dream
ゲーミング向け Xe アーキテクチャ Xe-HPG の存在が明らかにされているが、 Xe-LP と Xe-HP どちらの EU構成を踏襲するかはまだ分かっていない。
パッチでは他に、ハードウェアから整数除算演算器が外されたことや、倍精度演算対応のためと思われる 64-bitレジスタについても触れられている。