Intel は 2020/08/13 にバーチャルイベント「Architecture Day 2020」開催、次世代 CPU/GPU のアーキテクチャ詳細、次々世代 CPU/GPU の概要を発表した。
記事タイトルにある通り個人的なまとめであり、あえて取り上げていない内容もある。これまでの情報と結びつけるメモ書きに近い。
内容の網羅、特に Tiger Lake の詳細情報を望む方は以下を確認していただきたく思う。
- Intel Delivers Advances Across 6 Pillars of Technology, Powering Our Leadership Product Roadmap | Intel Newsroom
- Fact Sheet: - intel-2020-architecture-day-fact-sheet.pdf
- VimeoArchitecture Day 2020 (Event Replay)
Index
CPU
Alder Lake は Golden Cove と Gracemont のハイブリッド構成
ハイブリッドコア構成を採用する Alder Lake が、次々世代Coreアーキテクチャ Golden Cove 、次世代Atomアーキテクチャ Gracemont を組み合わせたものであることが明かされた。
性能ではクライアント向けをカバーしつつ、優れた電力比性能を発揮するとしている。
GPU
Xe-HP は 1-Tile 512EU
Xe-HP GPU はコアとなる Tile から構成され、Tile数は 1-Tile から 2-Tile、または 4-Tile となる。複数のタイルはマルチコアGPU であるように動作し、高いスケーリング性能を持つ。
複数の Tile は 1つのパッケージに収められ、Tile 間は EMIB 技術で接続される。
また、製造プロセスは Intel 10nm Enhanced SuperFin とされており、Tiger Lake や DG1 の製造プロセスから次世代のものとされる。
そして、下記画像は、動画内で Xe-HP のスケーリング性能を示すデモを行なった時のスクリーンショットだが、ログの部分に Compute units: 512 と表示されている。

ログの内容から、実行しているソフトウェアは clpeak は思われる。先日、自分が RX 560 で CU数のスケーリング性能を調査した時にも使ったもので、ログのフォーマットが一致する。
Platform: AMD Accelerated Parallel Processing Device: gfx803 Driver version : 3137.0 (HSA1.1,LC) (Linux x64) Compute units : 16 Clock frequency : 1196 MHz Single-precision compute (GFLOPS) float : 2356.53 float2 : 2314.70 float4 : 2265.87 float8 : 2248.82 float16 : 2207.62
この時 Compute units の行に表示されるのは、シェーダープロセッサ数ではなくそれを多数内包する CU (AMDGPU)、EU (Intel GPU) の数だ。
よって、Xe-HP は 1-Tile 512EU と考えられる。
ただ、RX 560 を使った調査の時にも書いたが、clpeak はメモリ性能が影響しないベンチマークソフトウェアであり、それもあって性能が単純にスケーリングしやすくなっている。
マルチGPU構成であっても性能がスケーリングすることを示す目的があるのかもしれないが、もっと大規模な、メモリが重要となるソフトウェアの場合、どこまでスケーリングするかはデモから測ることができない。
ゲーミング向け Intel GPU Xe-HPG
ゲーミング向けに最適化された Xe系アーキテクチャ、Xe-HPG の存在が明らかにされた。
Xe-LPの優れた電力比グラフィック性能、Xe-HPのスケーリング性能、Xe-HPCの最適化された周波数を組み合わせたアーキテクチャとしている。
メモリには帯域と帯域あたりの消費電力に優れる HBM系ではなく、コスト比に優れる GDDR6 を採用するとしている。
ハードウェアレイトレーシングもサポートし、その他グラフィック向けの機能も多くサポートする。
外部ファウンダリによって製造され、2021年に出荷予定。
Xe-LP アーキテクチャ詳細
これまでにもちょくちょく OSS から判明した Xe-LP /Gen12アーキテクチャ の構成を記事にしてきたが、今回公式により詳細が語られた。
EU部は前世代の Gen11アーキテクチャ が以下のように、Thread Control を EUごとに持ち、演算部が 4-wide FP/INT ALU と 4-wide FP/Extend Math ALU となり、浮動小数点演算では SIMD8 を構成していたのに対し、
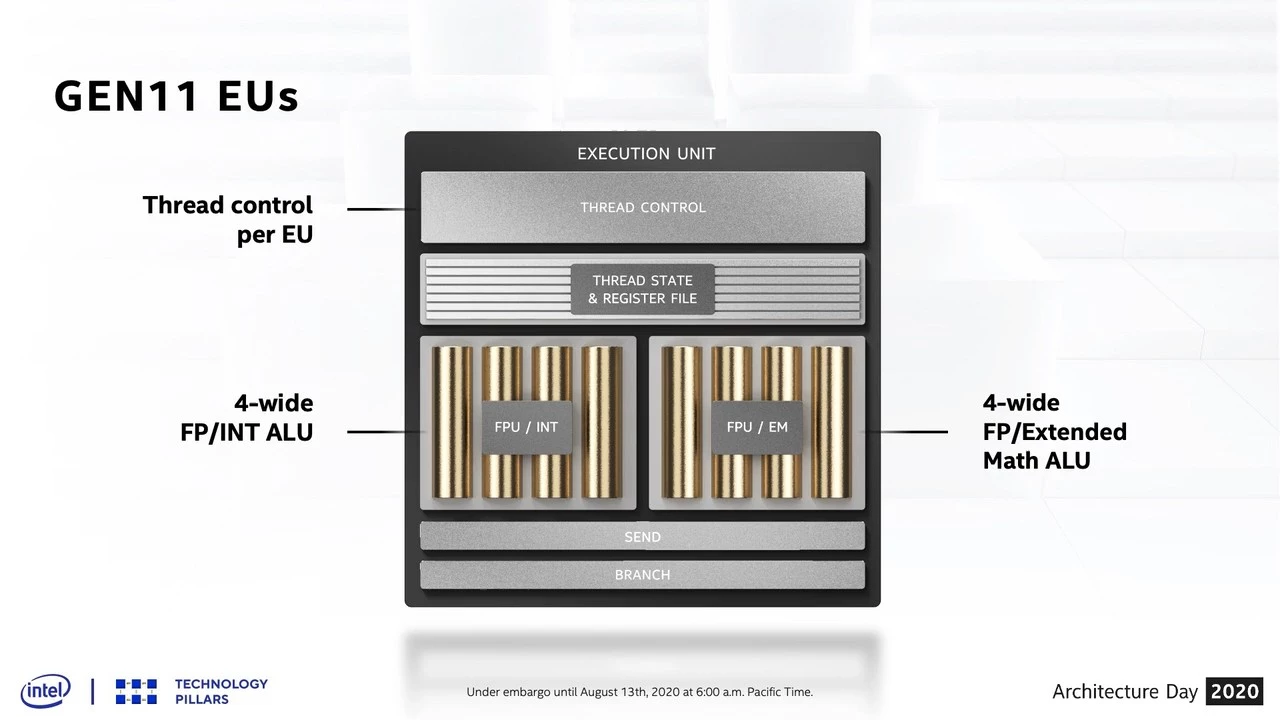
Gen12アーキテクチャ では、Thread Control が 2つ EU をペアとし、またがるものとなった。
演算部は、8-wide FP/INT ALU で SIMD8 を構成するものとなり、データ精度 INT16 を INT32時の 2倍、INT8 は 4倍のスループットで処理可能となった。複雑な計算を処理する Extend Math ALU は EU ごとに 2-wide となり、そこは Gen11アーキテクチャ より減っている。

キャッシュ構成としては、Sub-Slice 内に L1 Data Cache(L1/Tex$) が新設され、L3 Cache は最大 16MBを取ることが可能となっている。DG1は以前より L3 Cache 16MB であることが判明していたが、それが Xe-LPアーキテクチャとして最大の容量であるようだ。1
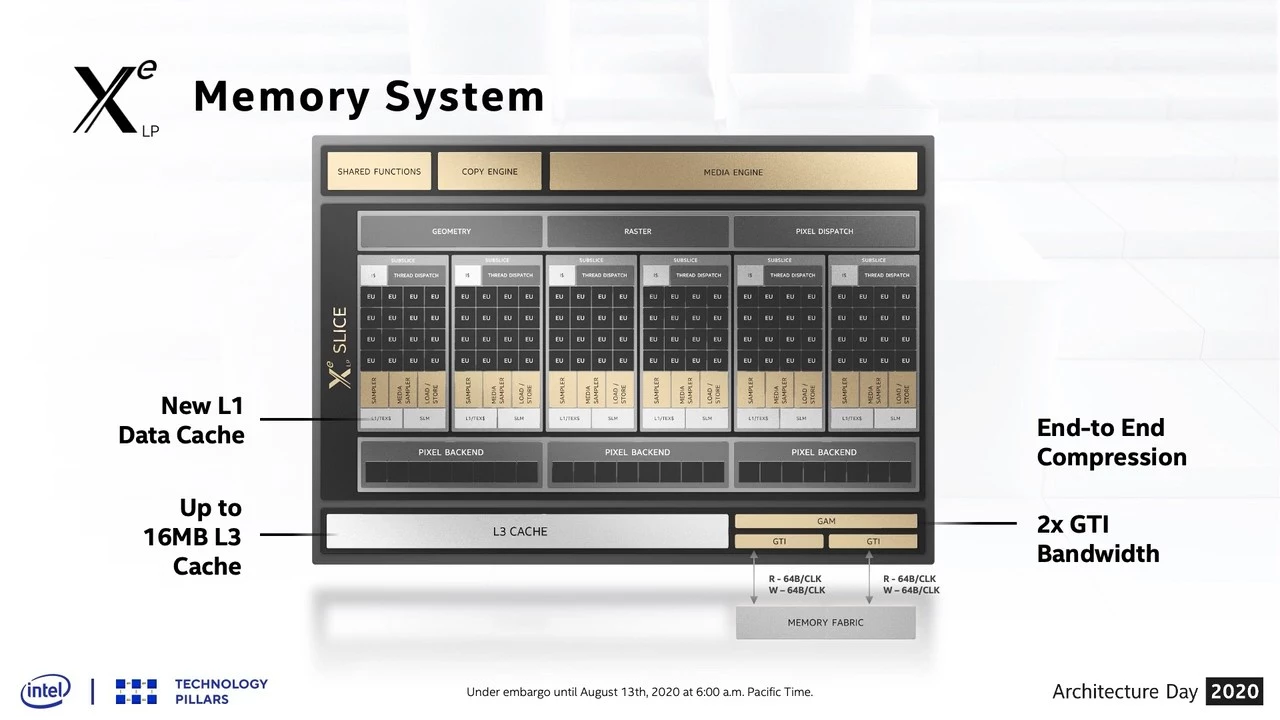
この L1 Data Cache だが、ブロック内には L1/Tex$ とあり、これまで Sampler部に含まれていた Tex$(Texture Cache) を汎用的に使えるよう移動させたと考えていいのだろうか。
EU、Texture Sampler、Pixel Backend 等のコア/エンジン部は前世代から 1.5倍の規模となった。
ただ Pixel Backend に関しては、DG1 と TGL GT2 は intel/compute-runtime から前世代と変わらない 16 pixels/clock であるように読めるが2、果たして単なる自分の読み違いか、それとも 24 pixels/clock の Xe-LPアーキテクチャベースの GPU が別に存在するのか。

また、OSS 等では Xe-LP /Gen12アーキテクチャ より、Sub-Slice ではなく Dual Sub-Slice と記述されるようになったが、その真意は明らかにはならなかった。
Texture Sampler は 12 Sub-Slices (6 Dual Sub-Slices) 相当であるため、グラフィック部を減らし、Sub-Slice 内の EU を増やすことでコンピュート性能重視とする策とも違うだろう。
新設された L1 Data Cache を共有する単位としての Dual Sub-Slice なのだろうか?
Xe-LPベースのサーバー向けGPU SG1
Tiger Lake GPU 、DG1 同様に Xe-LPアーキテクチャ をベースとする、サーバー向けのディスクリートGPU SG1 (Server GPU) の存在が明らかにされた。
小型フォームファクタで構築するデータセンターや低レイテンシで高密度な Android 向けクラウドゲーミング、映像ストリーミングサービスをターゲットとしている。
今年後半に出荷される予定であり、まもなく生産を開始するとしている。
(追記)AnandTech によると、SG1 は DG1 と同じシリコンダイ 4個を 1つのボードに搭載する形で製品化されるとのこと。
Intel’s SG1 is 4x DG1: Xe-LP Graphics for Server Video Acceleration and Streaming
てっきりメディア部を異常に強化させたXe-LPベース GPU かと思っていた。
-
Intel、DG1 において OpenCL と oneAPI Level Zero をサポート ―― 巨大なキャッシュを持つ DG1 | Coelacanth’s Dream
Intel、media-driver に DG1 へ向けたパッチを投稿 ―― GPGPUに傾いた DG1 のキャッシュ設定 | Coelacanth’s Dream ↩︎ -
https://github.com/intel/compute-runtime/blob/68294a0d68adfdf11236c18050c926e488d1a057/opencl/source/gen12lp/hw_info_dg1.inl#L138
https://github.com/intel/compute-runtime/blob/68294a0d68adfdf11236c18050c926e488d1a057/opencl/source/gen12lp/hw_info_tgllp.inl#L136 ↩︎