今回、Linux Kernel における AMDGPUドライバーのある機能を使って、RX 560 の一部有効 Compute Unit を無効化し、CU数がどれだけ GPU性能に影響を与えるのかを調査してみた。
Index
動機
今回の調査を行なったきっかけは、Renoirが最大 8CUと、前世代の Picassoの最大 11CUより少なく、また、Renoir ベースのモデルが持つ CU数がそれぞれ 1CU差と、CU数だけで見ればそう差はなかったことだったように思う。
それが GPU性能において CU数はどれだけ影響を与えるかを調べる動機となった。
より本音を言えば、AMDGPUドライバーに面白そうな機能があり、それを意義あることに使えないかという方が強いきっかけ、動機である。
しかし、真面目に考えれば、同じ GPU ASIC をベースにした製品、モデルであっても、基本 CU数の変更だけでなく、クロックの調整やメモリバス幅、L2cacheサイズの削減によって製品間の差別化が為されるため、CU数が性能にどれだけ影響を与えるかは測れない。
また、同種の GPU ASIC であっても、それぞれ異なる電圧特性を持つ。
そのため、同じ GPU で CU数だけを変えるということでしか性能への影響を測ることは難しく、その調査を実施することに意義があるのではないかと考える。
disable_cu=0.0.0,0.0.1,1.0.0,1.0.1………
一部 CU の無効化は、AMDGPUドライバーの disable_cu というモジュールパラメーターに値をセットすることで可能となる。1
値には、無効化したい CU を se(ShaderEngine).sh(ShaderArray).cu(Compute Unit) のフォーマットで指定する。
これが最初わかりづらく、試した結果、自分が調査に使う RX 560 (Polaris11) の場合は以下の画像のように対応しているとわかった。
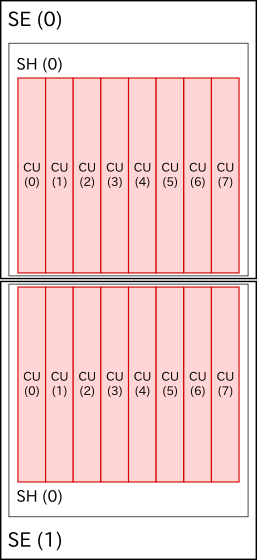
Polaris11 ShaderEngine.ShaderArray.CU
disable_cu=0.0.0 と値をセットすると、画像内の上側にある ShaderEngine に含まれる一番左の CU が無効化される。2
このパラメーターでは無効化する CU を 1つ1つ指定するため、各ShaderEngineのバランスを保ちながら 8CU を無効化したい時は、disable_cu=0.0.0,0.0.1,0.0.7,0.0.6,1.0.0,1.0.1,1.0.7,1.0.6 と長ったらしいパラメーターをセットする必要がある。左側 2CU、右側 2CU という風に無効化しているのは、4CU で共有する L1命令キャッシュ、L1スカラキャッシュのバランスも考慮したためである。
いちいち再起動前に /etc/default/grub を編集するのも手間であるため、起動時にその時限りのブートパラメーターに記述したが、それもそれで手間であった。
最大 16CU である RX 560 (Polaris11) で良かった。
それと、この機能には面白い点があり、ロードバランサーやスケジュールの観点などから、AMDGPU の ShaderEngine は通常それぞれ対称となるように設定されるが、disable_cu ではそれを無視して非対称な構成が可能となる。
使い道があるかと聞かれれば返答に窮するが、GPU情報を表示させると滅多に見られない Max compute units: 15 なんて文字列が出てきたりする。
この状態で、結果が配布元のサーバーに送信されるようなベンチマークを実行すれば、さぞ存在感を放つ奇妙な AMDGPU を登録できるだろう。有意義とは言いにくいが。
実際、これまでにそのような結果は見たことがないし、話題にもなっていない。disable_cu 自体は、実性能では単に性能を下げるだけであり、試したという人も見つからなかった。元から開発者向けのデバッグ機能であるため当然かもしれないが。
また、1CU での動作が可能か試したが、もれなく画面に現代美術的な絵が描かれた。
しかし、2CU での起動、動作が可能であったことから、各ShaderEngineに最低でも 1CU は有効であることが必須と思われる。
disable_cu は GFX9 までのサポートであり、RDNA世代 /GFX10 はサポートされていない。WGP(2CU)構成では片方の CU を無効化した際に問題が出るのだろうか。
調査環境
使用ソフトウェア
調査の際に実行するソフトウェアには 3つ選んだ。
RADV/ACO 検証の時にも用いた Vulkan API をサポートするコンピュート系の ncnn、
グラフィクス系 Vulkan ベンチマーク vkmark、
OpenCL で実行され、メモリ帯域と各精度の浮動小数点演算を測定可能な clpeak。
ncnn は Vulkan Computeオンリーであり、ベンチマーク機能も整備され、また深層学習における推論に用いられるネットワーク実行するため実際の使用状況に近い。
GPU の検証、調査にはうってつけと言えるだろう。
vkmark は、読み込むテクスチャやモデル数は少なく、3Dゲーム等の環境とは少し離れているが、オープンソースで開発され、プロプライエタリなベンチマークソフトのように結果の出力が制限されることもない。解像度は 1920x1080 に設定した。
clpeak は、GPU のメモリ帯域を測定できるオープンソースなベンチマークが clpeak くらいしか見つからなかったということと、ほぼ純粋な浮動小数点演算という CU数でスケールしやすいものが調査においては必要と思い、選択した。
システム環境
| System | |
|---|---|
| CPU | Ryzen 5 2600 6-Core/12-Thread (Boost 1T: 3.9GHz, Boost 12T: 3.7GHz) |
| RAM | DDR4 16GB (2993MHz) |
| GPU | RX 560 (Polaris11) 16CU, 128-bit 4GB Peak GFX: 1196MHz, Peak Mem: 1750GHz(7Gbps) |
| Linux Kernel | v5.7.8 |
| GPU UMD | Mesa 20.2.0-devel (git-a4c4e0103a) (RADV/ACO) |
| OpenCL | OpenCL 2.0 AMD-APP (3137.0) |
調査は 2CU /4CU /8CU /12CU /16CU の 5パターンで行なった。
GPUクロックに関しては、固定はせず、デフォルトの PowerTable 、プロファイルで実行した。
自分が所持する RX 560 は最大消費電力が 48W に設定されており、ベンチマークの中にはこれにギリギリまで近づいたものがあるため、固定してしまうと CU数の違いによる消費電力と発熱、そこからの GPUクロック選択が正常に行なわれない可能性がある。
デフォルトの PowerTable は以下。
RX 560
OD_SCLK: 0: 214MHz 715mV 1: 387MHz 721mV 2: 843MHz 737mV 3: 1011MHz 850mV 4: 1080MHz 912mV 5: 1126MHz 962mV 6: 1168MHz 1012mV 7: 1196MHz 1050mV OD_MCLK: 0: 300MHz 715mV 1: 625MHz 800mV 2: 1750MHz 850mV OD_RANGE: SCLK: 214MHz 1800MHz MCLK: 300MHz 2000MHz VDDC: 700mV 1150mV
結果
性能
ncnn ( Vulkan Compute )
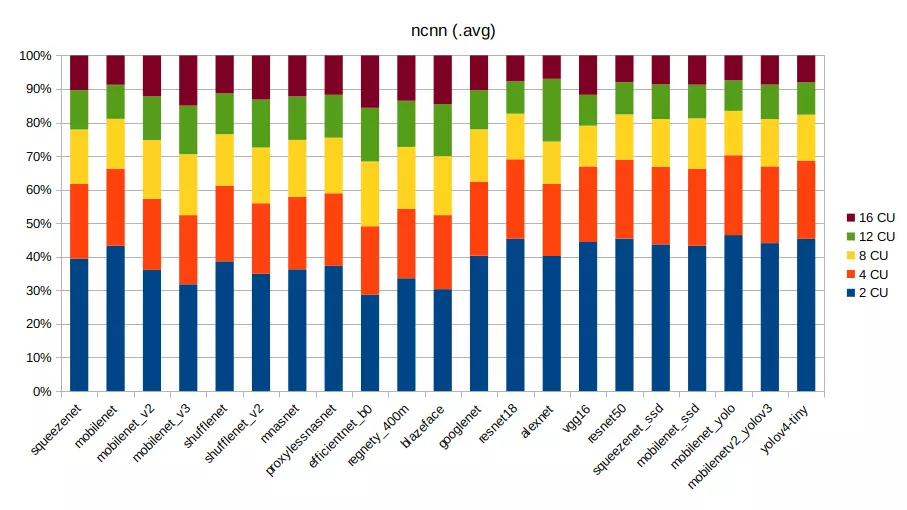
ncnn (Vulkan Compute)
| ncnn (.avg) (lower is better) \ Enable CU |
2 CU | 4 CU | 8 CU | 12 CU | 16 CU |
|---|---|---|---|---|---|
| squeezenet | 10.33 | 5.86 | 4.23 | 3.07 | 2.72 |
| mobilenet | 16.40 | 8.71 | 5.63 | 3.85 | 3.32 |
| mobilenet_v2 | 11.75 | 6.90 | 5.68 | 4.24 | 3.98 |
| mobilenet_v3 | 12.30 | 7.97 | 7.01 | 5.60 | 5.79 |
| shufflenet | 9.51 | 5.55 | 3.77 | 3.00 | 2.78 |
| shufflenet_v2 | 8.53 | 5.13 | 4.06 | 3.49 | 3.21 |
| mnasnet | 12.42 | 7.39 | 5.82 | 4.43 | 4.19 |
| proxylessnasnet | 13.56 | 7.87 | 6.02 | 4.65 | 4.27 |
| efficientnet_b0 | 23.61 | 16.82 | 15.89 | 13.17 | 12.86 |
| regnety_400m | 18.26 | 11.24 | 10.03 | 7.47 | 7.35 |
| blazeface | 2.78 | 2.02 | 1.61 | 1.42 | 1.33 |
| googlenet | 38.83 | 21.30 | 15.01 | 11.18 | 10.02 |
| resnet18 | 37.34 | 19.52 | 11.18 | 7.95 | 6.36 |
| alexnet | 64.04 | 34.15 | 20.16 | 29.74 | 11.10 |
| vgg16 | 217.13 | 110.01 | 59.50 | 44.95 | 57.42 |
| resnet50 | 88.95 | 46.11 | 26.32 | 18.80 | 15.64 |
| squeezenet_ssd | 58.60 | 31.07 | 19.03 | 13.81 | 11.63 |
| mobilenet_ssd | 36.89 | 19.57 | 12.79 | 8.56 | 7.45 |
| mobilenet_yolo | 77.89 | 39.85 | 22.12 | 15.31 | 12.42 |
| mobilenetv2_yolov3 | 36.89 | 19.14 | 11.79 | 8.59 | 7.30 |
| yolov4-tiny | 58.92 | 30.29 | 17.77 | 12.49 | 10.46 |
| (x) | 2CU → 4CU | 4CU → 8CU | 8CU → 12CU | 12CU → 16CU | 8CU → 16CU |
|---|---|---|---|---|---|
| squeezenet | 1.76 | 1.39 | 1.38 | 1.13 | 1.56 |
| mobilenet | 1.88 | 1.55 | 1.46 | 1.16 | 1.70 |
| mobilenet_v2 | 1.70 | 1.21 | 1.34 | 1.07 | 1.43 |
| mobilenet_v3 | 1.54 | 1.14 | 1.25 | 0.97 | 1.21 |
| shufflenet | 1.71 | 1.47 | 1.26 | 1.08 | 1.36 |
| shufflenet_v2 | 1.66 | 1.26 | 1.16 | 1.09 | 1.26 |
| mnasnet | 1.68 | 1.27 | 1.31 | 1.06 | 1.39 |
| proxylessnasnet | 1.72 | 1.31 | 1.29 | 1.09 | 1.41 |
| efficientnet_b0 | 1.40 | 1.06 | 1.21 | 1.02 | 1.24 |
| regnety_400m | 1.62 | 1.12 | 1.34 | 1.02 | 1.36 |
| blazeface | 1.38 | 1.25 | 1.13 | 1.07 | 1.21 |
| googlenet | 1.82 | 1.42 | 1.34 | 1.12 | 1.50 |
| resnet18 | 1.91 | 1.75 | 1.41 | 1.25 | 1.76 |
| alexnet | 1.88 | 1.69 | 0.68 | 2.68 | 1.82 |
| vgg16 | 1.97 | 1.85 | 1.32 | 0.78 | 1.04 |
| resnet50 | 1.93 | 1.75 | 1.40 | 1.20 | 1.68 |
| squeezenet_ssd | 1.89 | 1.63 | 1.38 | 1.19 | 1.64 |
| mobilenet_ssd | 1.89 | 1.53 | 1.49 | 1.15 | 1.72 |
| mobilenet_yolo | 1.95 | 1.80 | 1.44 | 1.23 | 1.78 |
| mobilenetv2_yolov3 | 1.93 | 1.62 | 1.37 | 1.18 | 1.62 |
| yolov4-tiny | 1.95 | 1.70 | 1.42 | 1.19 | 1.70 |
vkmark ( Vulkan Graphics )
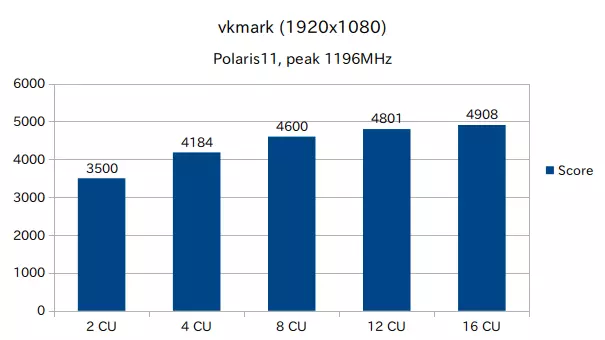
vkmark (1920x1080)
clpeak ( OpenCL Compute )
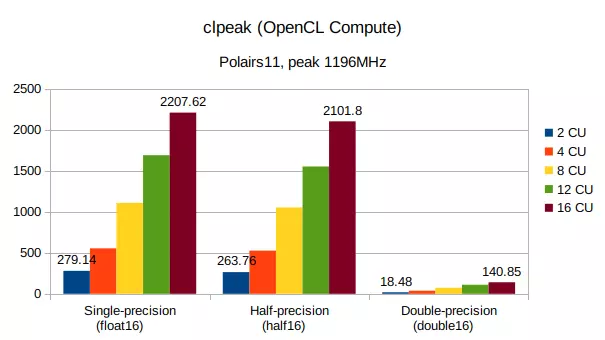
| clpeak (higher is better) \ Enable CU |
2 CU | 4 CU | 8 CU | 12 CU | 16 CU |
|---|---|---|---|---|---|
| Single-precision (float16) | 279.14 | 554.13 | 1108.97 | 1688.56 | 2207.62 |
| Half-precision (half16) | 263.76 | 525.95 | 1052.29 | 1552.16 | 2101.80 |
| Double-precision (double16) | 18.48 | 36.91 | 73.78 | 110.77 | 140.85 |
clpeak ( Global memory bandwidth )
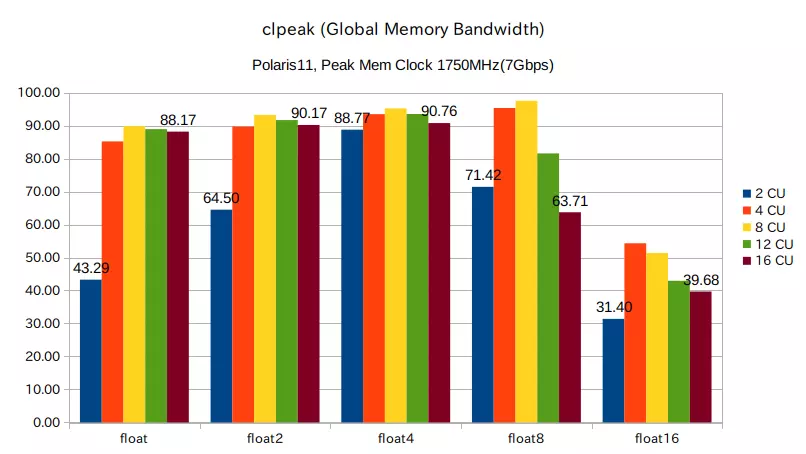
| clpeak (Global memory bandwidth) (higher is better) \ Enable CU |
2 CU | 4 CU | 8 CU | 12 CU | 16 CU |
|---|---|---|---|---|---|
| float | 43.29 | 85.19 | 89.82 | 88.92 | 88.17 |
| float2 | 64.50 | 89.71 | 93.25 | 91.67 | 90.17 |
| float4 | 88.77 | 93.47 | 95.18 | 93.51 | 90.76 |
| float8 | 71.42 | 95.32 | 97.51 | 81.57 | 63.71 |
| float16 | 31.40 | 54.32 | 51.36 | 42.93 | 39.68 |
考察
clpeek (OpenCL Compute) の結果から考えるが、まず half(半精度)、float(単精度)、double(倍精度)の後に続く数字は要素数を表す。
そして、2CU と 16CU の結果を比較すると、half16 で 7.96倍、float16 で 7.90倍、double16 で 7.62倍と、目論見通り? に CU数に従って綺麗に結果がスケールしている。
これは、clpeak (OpenCL Compute) はモニタした限りではメモリアクセスの頻度が小さく、演算自体は小規模であったためと思われる。
clpeak (Global memory bandwidth) においては、2CU の結果が全体的に低いが、これは VRAM が 4x GDDR5 32-bit であるのに対し、2CU ではそれを十分に満たすだけのロード/ストア命令を発行できなかったのではないかと思う。またはメモリレイテンシを隠蔽するのに十分なスレッド数を発行できなかったか。
ただ、2CU の結果が float では半分近くであるのに対し、そこから要素数を増やした float2 、float4 、float8 ではメモリ帯域が伸び、float4 では他の CU数設定と変わらないものとなっている。要素数が増えたことで、生成される Wave数もまた増えたのかもしれないが、自信は無い。
4CU 、8CU の結果が全体的に優れており、12CU 、16CU ではそれよりも落ち込む場合が見られる。うまい理由が思いつかないが、OpenCLドライバーによる影響があるのかもしれない。float16 では全体的に低い結果となったが、これも同様。
vkmark (Vulkan Graphics) では、4CU ずつ増やした結果を見ると、4CU -> 8CU では約1.09倍(+416スコア)、8CU -> 12CU では約1.04倍(+201スコア)、12CU -> 16CU では約1.02倍(+107スコア) となっており、性能向上の具合が鈍化している。
グラフィクス処理では、レンダリング結果をメモリ(フレームバッファ)に書き込んだり、テクスチャ等を格納する関係上、メモリ性能が重要とされることが多い。
今回の調査では CU数だけを減らし、メモリバス幅、L2cache、RenderBackend、最高GFXクロック等は変わらないため、それが vkmark の結果において支配的であり、CU数の増加があまり性能向上に影響しなかったものと思われる。
2CU -> 4CU では約1.19倍と大きな性能向上が見られるが、これは上記 clpeak (Global memory bandwidth) と同様にロード/ストア命令の発行レートがメモリ性能に影響している可能性がある。
ncnn では、コンピュート性能(CU数)とメモリ性能のどちらが重要となるかは、21個の各ネットワークモデルで異なる。
4CU ずつ増やした結果では、4CU -> 8CU と同等(±0.05)、またはそれよりも大きい性能向上を 8CU -> 12CU で得ているネットワークモデルは 6個程確認できる。これらはまだメモリ性能がボトルネックにはなっておらず、コンピュート性能(CU数)が結果に反映されているものと思われる。
しかし、12CU -> 16CU からは 8CU -> 12CU と同等以上の性能向上を得られているネットワークモデルはない。ここはコンピュート性能に対し、メモリ性能が追い付かなくなったものと推察される。
alexnet に関しては、12CU -> 16CU で劇的に性能向上しているように見えるが、8CU から 12CU で見るとかえって性能が悪化しているため、何らかの理由で 12CU での結果が特別悪化したものと思われる。
総論
実際の使用感に近い ncnn (Vulkan Compute) と vkmark (Vulkan Graphics) の結果から、ある程度の CU数からさらに CU数を増やしても単純に性能は向上せず、メモリ性能がボトルネックになっているものと考えられる。
GPU において、帯域あたりの電力効率に優れる HBM2 への取り組みがどれだけ重要か窺える。
Zen 2 APU Renoir にて LPDDR4x-4266 に対応したことは AMD において必須だったのだろう。
結論として、ただ CU数を増やしても GPU性能はそれに応じた性能向上幅を見せ続けてはくれず、どこかでメモリ性能がボトルネックとなってくる。
Renoir ベースの製品モデルは、モデル間で CU数だけでなく、クロックでも差別化を行なっている。
グラフィクス性能という点では、RenderBackend 等にも反映されるクロックの方が影響を持つだろう。
また、性能向上幅と clpeak (Global memory bandwidth) の結果から、Polaris11 におけるコンピュート性能(CU数)とメモリ性能のバランスは、8CU または 8CU と 12CU の間あたりが最も取れているのではないだろうか。
AMD が Polaris11 の下位 ASIC として、CU数のみを 6基減らした Polaris12 を設計した理由が自分の中で疑問としてあったが、より CU数とメモリ性能のバランスが取れ、
CU数を減らしたことでダイサイズが抑えられ、コストと電力効率に優れる GPU ASIC を必要としたのかもしれない。
実行中の消費電力も計測したけど【消費電力編】はまたいつか。メモリクロックを 300 /625 /1750 MHz のどれかに固定してメモリ性能の影響を測るのもまたいつか。