改めて Aldebaran GPU 関連のパッチを読んでいた所、以下のような記述が見つかった。
レジスタに特定の値をセットし、GPU の内部設定を行う部分がダイ 2種類分用意されている。
+static const struct soc15_reg_golden golden_settings_gc_9_4_2_alde_die_0[] = { + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_0, 0x3fffffff, 0x141dc920), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_1, 0x3fffffff, 0x3b458b93), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_2, 0x3fffffff, 0x1a4f5583), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_3, 0x3fffffff, 0x317717f6), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_4, 0x3fffffff, 0x107cc1e6), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_5, 0x3ff, 0x351), +}; + +static const struct soc15_reg_golden golden_settings_gc_9_4_2_alde_die_1[] = { + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_0, 0x3fffffff, 0x2591aa38), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_1, 0x3fffffff, 0xac9688B), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_2, 0x3fffffff, 0x2bc3369B), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_3, 0x3fffffff, 0xfb74ee), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_4, 0x3fffffff, 0x21f0a2fe), + SOC15_REG_GOLDEN_VALUE(GC, 0, regTCP_CHAN_STEER_5, 0x3ff, 0x49), +}; +
以下のコードを見る限り、想定しているダイ数は 2個 まで であり、それより多いダイは無効化、無視される。
/* apply golden settings per die */ switch (die_id) { case 0: soc15_program_register_sequence(adev, golden_settings_gc_9_4_2_alde_die_0, ARRAY_SIZE(golden_settings_gc_9_4_2_alde_die_0)); break; case 1: soc15_program_register_sequence(adev, golden_settings_gc_9_4_2_alde_die_1, ARRAY_SIZE(golden_settings_gc_9_4_2_alde_die_1)); break; default: dev_warn(adev->dev, "invalid die id %d, ignore channel fabricid remap settings\n", die_id); break; }
2-Die というのはそれなりに納得のいく数字で、というのも、パッチが投稿された時の記事で XGMI/Infinity Fabric Link に最適化された SDMAエンジンが 3基と、Arcturus よりも少ない、半分の数になっていると書いた。
それが 2-Die 構成であれば、XGMI/Infinity Fabric Link 用の SDMAエンジンは計 6基となり、いつかに示されたようなコーダルリング状のネットワークによる 8-GPU のトポロジが構成可能になる。
static const struct kfd_device_info arcturus_device_info = { .asic_family = CHIP_ARCTURUS, .asic_name = "arcturus", .max_pasid_bits = 16, .max_no_of_hqd = 24, .doorbell_size = 8, .ih_ring_entry_size = 8 * sizeof(uint32_t), .event_interrupt_class = &event_interrupt_class_v9, .num_of_watch_points = 4, .mqd_size_aligned = MQD_SIZE_ALIGNED, .supports_cwsr = true, .needs_iommu_device = false, .needs_pci_atomics = false, .num_sdma_engines = 2, .num_xgmi_sdma_engines = 6, .num_sdma_queues_per_engine = 8, }; static const struct kfd_device_info aldebaran_device_info = { .asic_family = CHIP_ALDEBARAN, .asic_name = "aldebaran", .max_pasid_bits = 16, .max_no_of_hqd = 24, .doorbell_size = 8, .ih_ring_entry_size = 8 * sizeof(uint32_t), .event_interrupt_class = &event_interrupt_class_v9, .num_of_watch_points = 4, .mqd_size_aligned = MQD_SIZE_ALIGNED, .supports_cwsr = true, .needs_iommu_device = false, .needs_pci_atomics = false, .num_sdma_engines = 2, .num_xgmi_sdma_engines = 3, .num_sdma_queues_per_engine = 8, };
ただ、それもやはり、記述されている SDMAエンジンの数が GPU全体ではなくダイごとのもので、ダイ同士の接続は SDMAエンジンを用いる XGMI 接続ではない必要が出てくる。
Intel の Xe-HP も 1パッケージ内に EMIB技術による複数の GPUチップ (タイル) を搭載する MCM構成を取っているが、メモリアクセスについては各 GPU に接続された HBM2eメモリが最も高速であり、他の GPU に接続されたメモリはそれよりも遅くなる。
Xe-HP のあるタイルに接続されたメモリと、他の GPU に接続されたメモリを区別するパッチは既に投稿されており、Aldebaran も MCM構成を採るのであればドライバー側でそれを意識する必要があるように思われる。
Intel Xe GPU 近況 ―― Xe-HPのメモリリージョン, PXP, Iris Xe MAX のサポート状況 | Coelacanth’s Dream
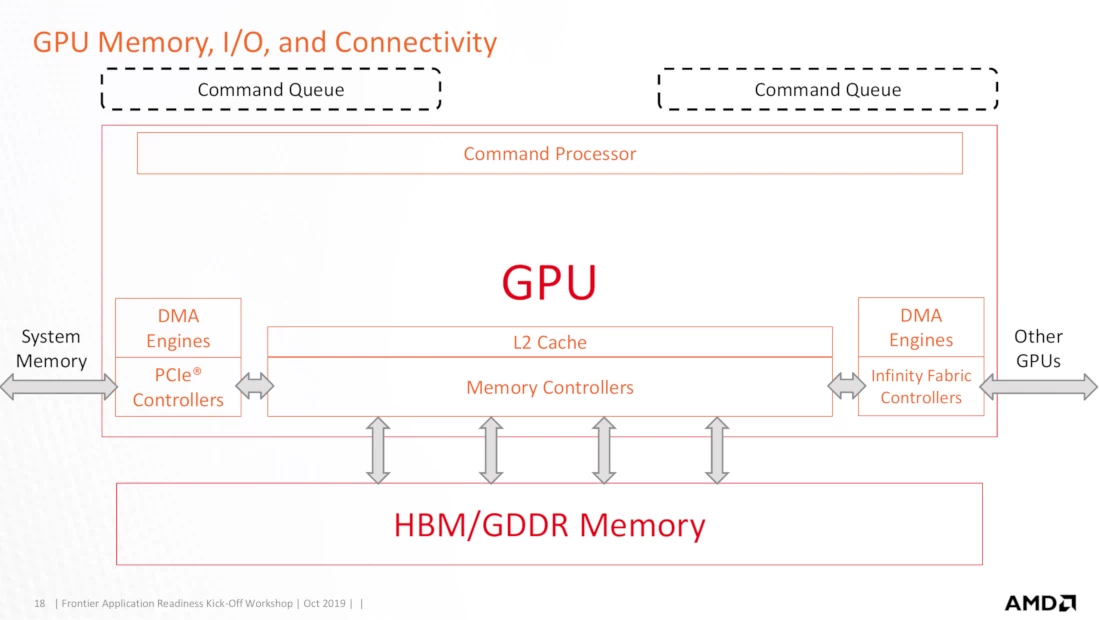
GPU Memory, I/O, and Connectivity
画像出典: ORNL_Application_Readiness_Workshop-AMD_GPU_Basics.pdf
TCX
Aldebaran GPU の謎をもう1つ挙げると、Aldebaran では TCX という GPUブロックが追加されている。
Linux Kernel のドライバー部を見る限りでは Aldebran 関連のファイルのみに TCX は出てきている。
+ /* TCX */ + { SOC15_REG_ENTRY(GC, 0, regTCX_EDC_CNT), 0, 1, 2 }, + { SOC15_REG_ENTRY(GC, 0, regTCX_EDC_CNT2), 0, 1, 2 },
まあ謎と言ったように、具体的な機能は不明だし、名前の意味も不明。
そも、GPUブロックについては、TCP が CU内の L1ベクタキャッシュ (GCN) を意味し、TCC は L2キャッシュを意味するということくらいはコード中のコメント等で語られていたりするが、名前自体の意味は隠されていることがほとんどである。TCC は Texture Channel Cache の略と考えられるが、他は不明。
TCX はコードから 15グループ存在しているとも読めるが、それくらいしか読めるところは無かった。
パッチにしろ、正式発表にしろ、その後の公式資料にしろ、その内公式から語ってくれるだろうから、ただそれを待つ。