先日、LLVM にサポートが追加された GPUID gfx90a を用いると思われる MI200 だが、すでにスーパーコンピューター Frontier と LUMI へ採用されており、2021年中に納入、一部運用を開始する予定にある。
LLVM に GFX90A のサポートが追加される ―― CDNA 2/MI200 か | Coelacanth’s Dream
Frontier は 2021年にシステムを納入予定としているが、LUMI は 2021半ばから運用を開始する予定で進められている。
Index
Frontier と LUMI
Frontier と LUMI をざっくりと説明すれば、どちらも AMD CPU + AMD GPU の構成で構築されるスパコンである。そして GPU には MI200 が採用される予定にある。
CPU にはどちらにも Trento の名があるが、そのコードネームを持つ EPYC CPU について AMD から直接語られたことはまだない。
しかし、Frontier のノード構成と発表内容から、CPU は Zen 3 アーキテクチャ (Milan と同じチップレット?) を採用し、GPU との XGMI/Infinity Fabric Link 対応に I/Oチップレットを拡張させたものではないかと予想されている。


2つの大きな違いは目標とするピーク性能とスケジュールにあり、Frontier はピークFP64演算性能 1.5 EF を目標に掲げるエクサスケールシステムだが、LUMI は 552PF のプリエクサスケールシステムとなる。
Frontier は LUMI の約 2.7倍のピークFP64演算性能を持つが、スケジュールは 2021半ばに設置、2022年後半から運用を開始、となっている。1
LUMI は 2019年11月から 2020年8月にかけてシステムを調達、2020年Q4には納入するデータセンタを準備、そして 2021年半ばにはもう運用を開始する予定にあるが、それは GPU をメインとしたパーテーション以外となる。そのパーテーションは 2021年Q4 に設置される予定。
それでも他のパーテーションに GPU は搭載され、GPU をメインとするパーテーションも 2021年Q4 と Frontier よりも早いことから、LUMI は MI200 を採用したスパコンとして最初に稼働するものになると思われる。2
他の情報にも触れると、Frontier の納入先は米エレルギー省管轄下にあるオークリッジ国立研究所、LUMI はフィンランドに拠点を置く EuroHPC JU (European High Performance Computer Joint Undertaking) となる。LUMI は欧州10ヶ国 (ベルギー、チェコ共和国、デンマーク、エストニア、フィンランド、アイスランド、ノルウェー、ポーランド、スウェーデン、スイス) で共有される。
契約の総額は Frontier が $600M (6億ドル)、LUMI が $160M (1億6,000万ドル)。
LUMI は予定通り 2021年中に運用が開始されれば、ピークFP64性能では現在世界最速のスパコン、富嶽 (Fugaku) の 513 PetaFlops を越すとされる。
しかし、LUMI の HPL (Linpack) での性能は 375 PF とされ、対して富嶽は 442.01 PF の性能を発揮しており、実行性能や実行効率では富嶽がまだ勝っている。
LUMI の構成
LUMI は複数のパーテーションで構成され、パーテーション間は HPE Silingshot による高速なインターコネクト技術で接続される。
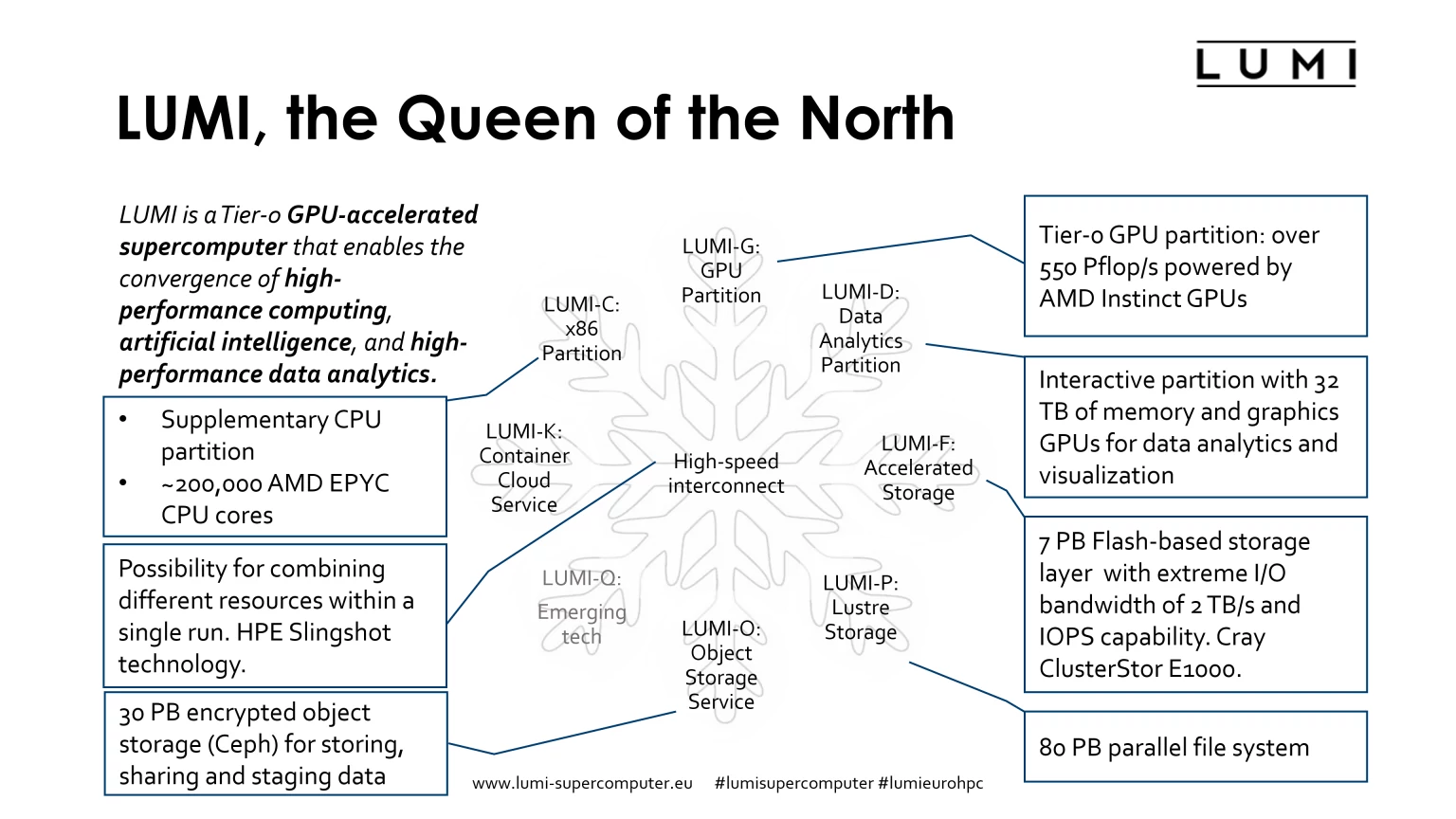
LUMI-G パーテーションに主要な CPU + GPUノードが搭載され、パーテーション内の GPU による総ピークFP64演算性能は 550 PFlops 以上になると言う。CPU + GPUノードの構成は Frontier と同じ 1 CPU : 4 GPU の構成になるとされている。Frontier も LUMI もプライムコントラクターとして HPE が関わっており、CPU、GPU が同世代となるとノード構成が同じになるのは自然だろう。3
前述したように、LUMI-G は他のパーテーションよりも遅れて 2021Q4 から運用が開始される。
LUMI-C は補助的なパーテーションとなり、GPU は搭載せず、CPU のみで構成される。
LUMI-C には 64-Core の AMD EPYC CPU を搭載することがすでに語られており、LUMI-C に搭載される総CPUコア数は 〜200,000コア (〜3125 EPYC CPU) にもなる。
上に載せた画像中に AMD Milan + Torento と書かれてあったが、恐らくは CPU + GPU のノードには Trento を採用し、CPU のみとなる LUMI-C には Milan が採用されるのだろう。
LUMI-D は巨大なデータ解析や前後処理用のパーテーションとされ、32TBのメモリと 64 GPU が搭載される。
32TB のメモリというのは CPU と GPU のメモリを合わせた容量となる。GPU のメモリサイズについて、仕様がまだ固まっていない頃の発言だが、少なくとも 40GB以上はあることが語られている。4
このことから、MI100 は HBM2 4096-bit 32GB (4スタック、スタックあたり 8GB) というメモリ仕様だったが、MI200 ではスタックあたり 16GB の容量が可能で、より高速な HBM2e を採用すると思われる。メモリバス幅を広げる、あるいは両方を採用する可能性もあるが、NVIDIA GA100 GPU がチップとしては HBM2e 6144-bit (6スタック) を持つが、製品としては歩留まり等から 1スタックを無効化していたことを考えると若干薄い可能性のように思える。
チップレットアーキテクチャなどである程度軽減可能な問題ではあるが。
ちょうど HPE の製品名に AMD Instinct MI200 OAM x1 MCM Special FIO Accelerator for HPE Cray EX があったことが話題になっている。5
Intel OneAPI - a50002555enw
64 GPUs が 64GB のメモリを持つとして 4TB、残り 28TB は CPU が持つものと思われる。
CPU と GPU のメモリ空間の統合は CDNA 2 アーキテクチャ と 3rd Gen Infinity Architecture で可能となることが以前に発表されている。
CPU + GPU という構成であっても LUMI-G と LUMI-D とで使い分けているのは LUMI システムの特徴的で面白い点と言える。
LUMI-F 、LUMI-P 、LUMI-O はストレージ用パーテーションとなり、LUMI-O にはデータセット等共有するデータが置かれる。
量子コンピューティング研究のための LUMI-Q も名前だけはあるが、詳細はまだ決められていない。
CUDAコードから HIPコードへの変換
ちょうど LUMI システムに向けた、CUDA用のコードを AMD GPU に対応している HIP (Heterogeneous Interface for Portability) コードに変換や移植する際の手順、性能についての発表が Fosdem 2021 で行われた。
発表内容は以下のリンク先で PDFと動画形式で公開されている。
CUDAコードを移植する方法は複数あるが、その中でも十分に使い慣れたものを選択し、可能な限り性能を発揮させる必要があるとし、性能が出ない場合は OpenMP を GPU にオフロードすることや、プロファイリングツールを駆使してデータ転送を最適化する、CU内の LDS (Local Data Share) を活用する等の方法を提案している。
また、CUDAコードと HIPコードの性能比較では、多くで同等か HIPコードがわずかに優れており、合計実行時間では HIPコードの方が少し掛かっているが約 2% のオーバーヘッドに収まっている。
参考リンク
- HPE、1億6,000万ドル超の世界最速スーパーコンピューターをフィンランドに構築する契約を獲得し、欧州の科学研究の発展と経済成長を支援 | HPE 日本
- LUMI resource allocation (Finland) - lumi-businessoulu_pekka_manninen_2020-11-26.pdf
- Karlin_P3HPC_2020 - P3HPC_Karlin_Day-2-.pdf
- The aftermath of the LUMI end user webinar - The aftermath of the LUMI end user webinar - CSC Company Site
- One of the world’s mightiest supercomputers, LUMI, will lift European research and competitiveness to a new level and promotes green transition - One of the world’s mightiest supercomputers, LUMI, will lift European research and competitiveness to a new level and promotes green transition - CSC Company Site
- May we introduce: LUMI - LUMI
-
Frontier: OLCF’S Exascale Future – Oak Ridge Leadership Computing Facility ↩︎
-
LUMI resource allocation (Finland) - lumi-businessoulu_pekka_manninen_2020-11-26.pdf ↩︎
-
LUMI resource allocation (Finland) - Webinar_LUMI_040221.pdf ↩︎
-
The aftermath of the LUMI end user webinar - The aftermath of the LUMI end user webinar - CSC Company Site ↩︎