AMD は SC20 の開催に合わせ、現地時間 2020/11/16 付で、初の CDNAアーキテクチャ 採用製品となる AMD Instinct™ MI100 、開発コードネーム Arcturus を発表した。
- AMD EPYC™ Processors and New AMD Instinct™ MI100 Accelerator Redefine Performance for HPC and Scientific Research :: Advanced Micro Devices, Inc. (AMD)
- AMD CDNA Architecture | AMD
- AMD Instinct™ MI100 Accelerator | AMD
Linux Kernel (amd-gfx) には丁度 Arcturus の実験的サポートのフラグを外すパッチが投稿されている。1
Index
MI100 スペック
Arcturus は ShaderEngine 8基、最大総 CU 数 128基という構成だが、MI100 では各 ShaderEngine 内の CU を 1基無効化し、総 CU 数 120基という仕様になっている。
動作クロックは最大 1502MHz。ピークFP64演算性能は 11.5TFLOPs に達し、10TFLOPs の壁を突破した初の GPU を謳う。
Vega20/MI50 では、3基以上を Infinity Fabric/XGMI を用いて接続する場合、リングバス構成となり、GPU 間でのデータ転送に幾許かの遅延が発生していた。2
だが Arcturus/MI100 では最大 4基での相互接続に対応し、より高性能な GPU トポロジを構成可能となる。
Arcturus は ネットワーク構造こそ変わるが
最大 8基のトポロジ構成に対応しているはずだが、MI100 では Infinity Fabric Link が 3本となっている。3
メモリバス幅は HBM2 4スタック (4096-bit)、容量は最大 32GB、ECCサポート、という点は Vega20/MI50 と変わらないが、メモリクロックは 0.2GHz 向上した 1.2GHz となり、ピークメモリ帯域は 1228.8GB/s となる。
また、HBM2メモリのメモリ階層 1つ上、L2キャッシュは Vega20/MI50 から倍の数に増やされ 32スライスとなり、L2キャッシュ容量は計 8MB。
製造プロセスは Vega20/MI50 と同じ TSMC 7nm FinFet とされ、大きく性能を向上させながらも TBP 300W を維持している。
CDNAアーキテクチャ
Arcturus/MI100 はグラフィクス処理を行なうための固定機能ユニット ジオメトリプロセッサ、ラスタライザ、RB (Render Backend)、ディスプレイエンジンさえも
を持たず、空いた分を利用して、CU の改良、強化、実装密度の大きな引き上げと、電力効率の向上を実現している。
そのため、GPU とそのアーキテクチャを活用したアクセラレータの境目は曖昧で、うまい言い方が思いつかないが
一般的な GPU への転用はできないものとなっている。
AMD も Arcturus/MI100 を GPU と呼びつつも、アクセラレータとしての見方が強いのか、ブランドを Radeon Instinct ではなく AMD Instinct としており、Radeon の名は使っていない。ニュースリリース内を Radeon で検索しても見つからなかった。
グラフィクス用の固定機能ユニットは持たないが、マルチメディアエンジンは搭載しており、用途としては機械学習のオブジェクト検出の際などを想定している。
また、Linux Kernel (amd-gfx) に記述されているコードによると、VCN (Video Core Next) のバージョンは 2.5 となり、それを 2基搭載している。4 HEVC、H.264、VP9 のデコードに対応。
各アーキテクチャの CU 比較
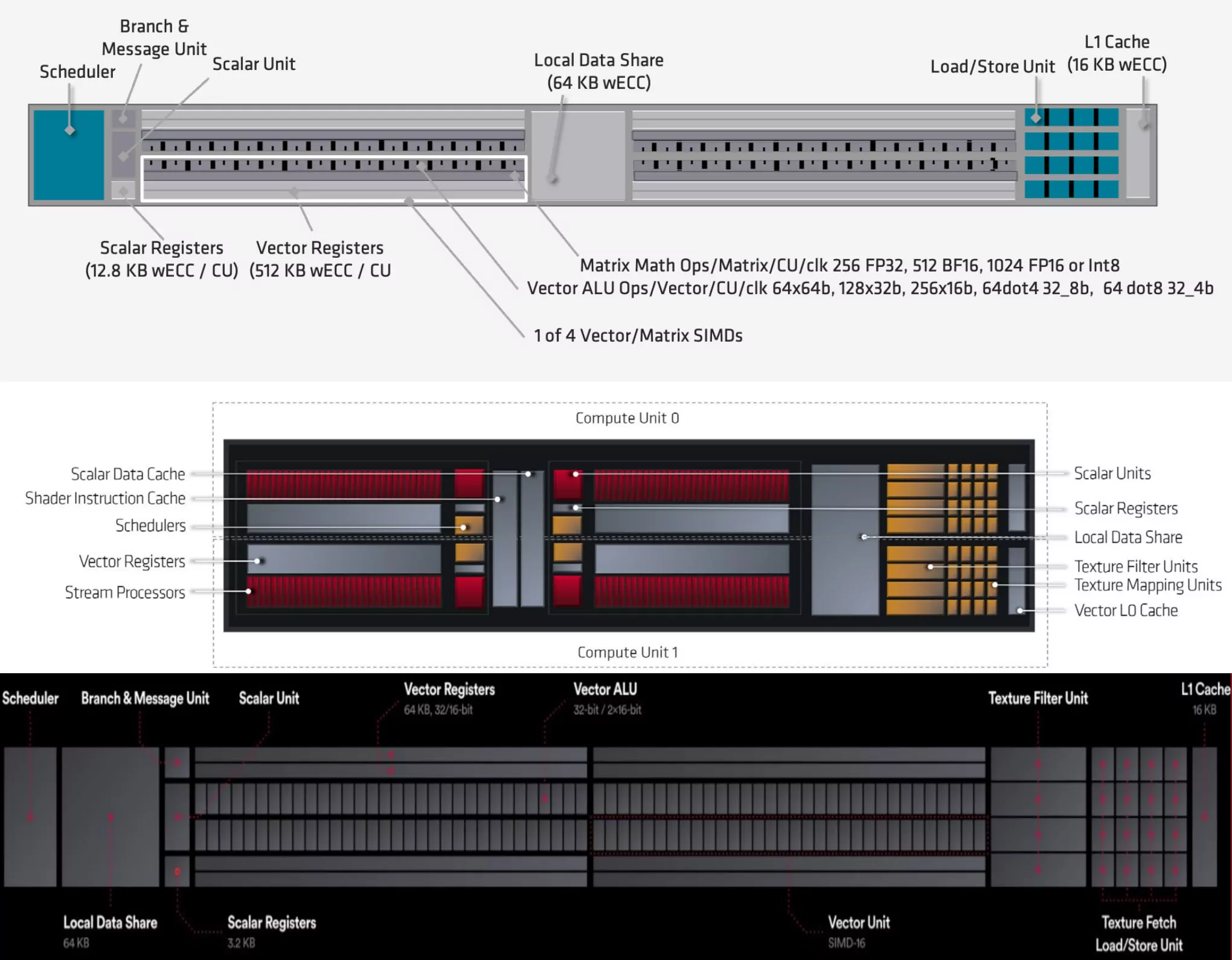
CDNA/RDNA/GCN CU
画像出典: amd-cdna-whitepaper.pdf (Page 6),
Introduction - rdna-whitepaper.pdf (Page 5),
M&E GBGH - HC29.21.120-Radeon-Vega10-Mantor-AMD-f1.pdf (Page 21)
丁度良い画像が見つからなかったため、少し不格好となってしまったが、上が CDNA/RDNA/GCN CU の各構造をまとめたものである。
CDNAアーキテクチャ の CU 全体は GCNアーキテクチャ のそれに似通っているが、SIMDユニットあたりのベクタレジスタ (VGPR) は、CU あたり 256KB (GCN) から 512KB (CDNA) と、倍の容量に増量されている。
その反面、スカラレジスタ (SGPR) は CU あたり 32KB (GCN) から 12.8KB (CDNA) と、半分の容量に減らされている。
RDNAアーキテクチャ はと言うと、CU あたりの総ベクタレジスタは GCNアーキテクチャ と変わらないが、スカラレジスタは 20KB となっている。
CDNAアーキテクチャ では CU内の各SRAM ベクタレジスタ、スカラレジスタ、LDS (Local Data Share)、L1キャッシュ
が ECC に対応しており、HBM2メモリと合わせてフルチップで ECC に対応している。
AMD GPU のコンパイラバックエンドとしても採用されている LLVM には、既に SRAM ECC への対応が行なわれている。Vega20/MI50 にもオプション自体は存在するが、デフォルトでは無効に設定されている。5
CDNAアーキテクチャ ではテクスチャフィルタユニットが省かれていることが分かる。 グラフィクス用の固定機能ユニットを省いたというのは CU 内部にも渡っている。
| Register Size per CU |
Vector | Scalar |
|---|---|---|
| GCN | 256KB | 32KB |
| RDNA | 256KB | 20KB |
| CDNA | 512KB | 12.8KB |
RDNAアーキテクチャとの SIMDユニット比較
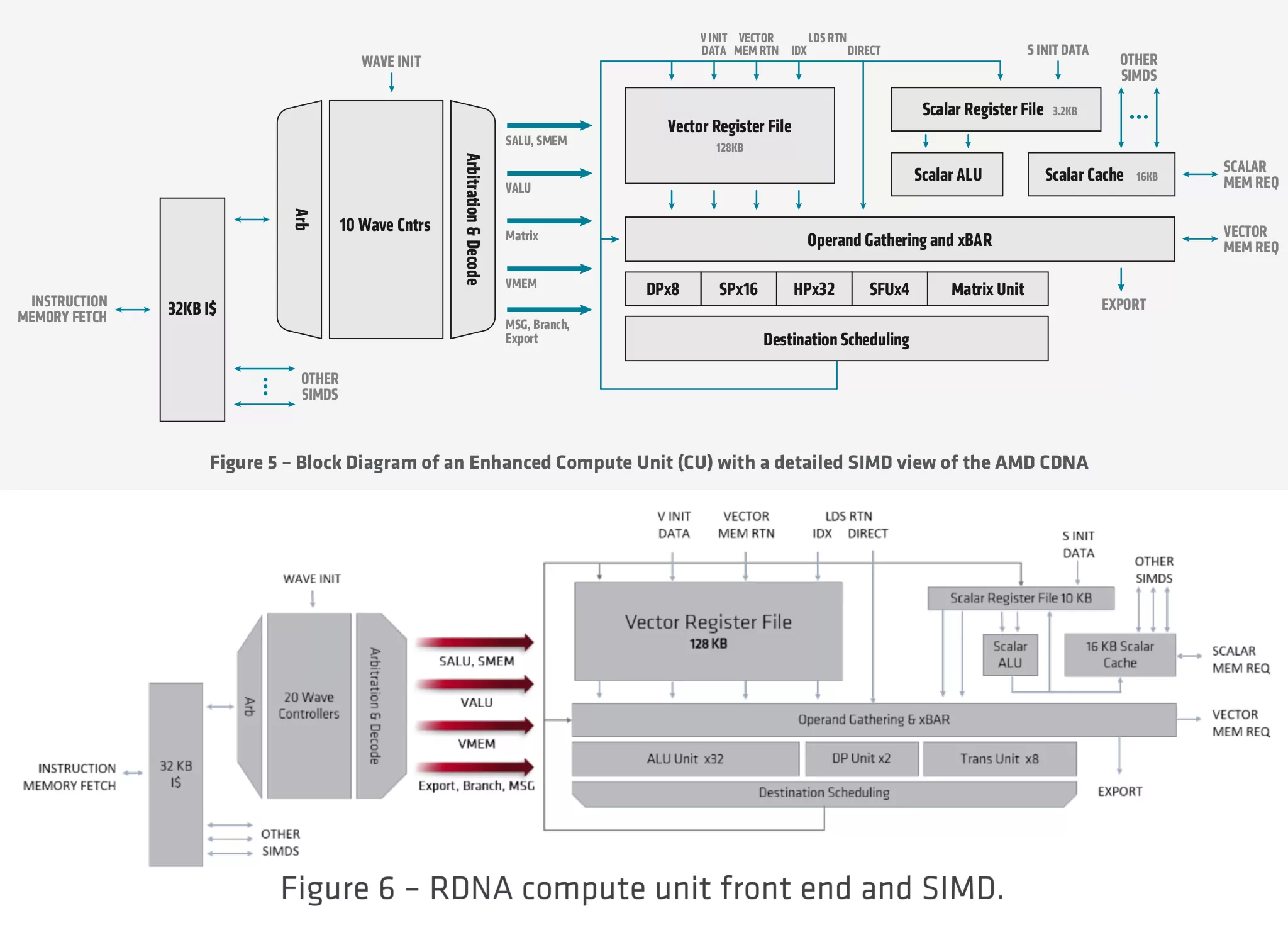
CDNA/RDNA SIMD
画像出典: amd-cdna-whitepaper.pdf (Page 6),
Introduction - rdna-whitepaper.pdf (Page 9)
上画像は CDNAアーキテクチャ と RDNAアーキテクチャ の SIMDユニットダイアグラムを比較したもの。GCNアーキテクチャ でも同様の画像を探したが見つからなかった。
SIMDユニットは 512-bit幅であり、ベクタパイプラインとしては 16-wide (SIMD16)。
Wave64 (64スレッド) を SIMD16ユニットで 4サイクル掛けて処理というのも GCNアーキテクチャ から変わらないものと思われる。
データセンタ、計算向けとしては、メモリレイテンシを隠蔽しやすいこの方式のが有利なのだろう。
SFU (Special Function Unit) は、CDNAアーキテクチャ では 4基と、ここも GCNアーキテクチャ と変わらない。RDNAアーキテクチャ では 8基となっているが、SIMD32ユニットあたりであるため、SIMD幅に対するバランスは同じである。
CU あたりの Wave Controller が保持する Wave数も GCN/RDNAアーキテクチャ と変わらず 40 Wave (10 Wave x4) となる。ただ、RDNA 2アーキテクチャ からは SIMDユニットあたり 16 Wave、CU あたりでは 32 Wave になると見られている。6
GCNアーキテクチャ から RDNA/CDNAアーキテクチャ への分化が始まってからというもの、AMD は CU、SIMDユニットの構造を大きく見直しているという印象を受ける。
CDNAアーキテクチャ では SPユニット (single-precision, FP32, 単精度) 16基に対し、DPユニット (double-precision, FP64, 倍精度) 8基を持つため、FP32演算の半分のレートでFP64演算を行なえる。RDNAアーキテクチャ では DPユニットが 2基であるため、1/16のレートとなる。
また、HPユニット (half-precision, FP16, 半精度) を別に 32基持つ。恐らくは SPユニットでの Packed実行と合わせて、FP32演算性能の 4倍となる 184.6TFLOPS というピークFP16演算性能が可能になっていると思われるが、どのような処理フローになっているかは不明。
LLVM のソースコードを見ると、Arcturus/MI100 (gfx908) に向けた v_pk_fmac_f16 命令の対応が追加されているが、これと関係しているのだろうか。7
新たに行列演算を高速に処理するための MFMA (Matrix Fused Multiply-Add) 命令に対応し、それを実行する Matrixユニットが増設された。データ精度は FP32、FP16、BF16 に対応する。
ベクタパイプラインを用いるよりも高速に処理が可能となり、行列演算では入力値の多くを再利用するためレジスタから読み出す回数が減り、これによって優れた電力効率で行列演算の処理が可能となっている。
Arcturus の情報はこのサイトを開設した以前から Linux Kernel 等へのサポートが追加されており、個人としても少しずつ情報を追ってきた。
Arcturus/MI100 が正式発表されたことをオタクとして (勝手だが) 本当に嬉しく思う。ニュースリリースを見た時はとても興奮し、心の底から Arcturus/MI100 の登場を祝福していた。
-
[PATCH] drm/amdgpu: remove experimental flag from arcturus ↩︎
-
Navi21 /Sienna Cichlid は高速なGPU間通信 XGMI をサポート | Coelacanth’s Dream ↩︎
-
AMD Financial Analyst Day 2020 個人的まとめ | Coelacanth’s Dream ↩︎
-
drm/amdgpu: enable VCN0 and VCN1 sriov instances support for Arcturus ↩︎
-
llvm-project/AMDGPUUsage.rst at master · llvm/llvm-project ↩︎
-
AMD Sienna Cichlid をサポートするパッチが OpenGL、Vulkanドライバーに投稿される | Coelacanth’s Dream ↩︎
-
[AMDGPU] gfx908 v_pk_fmac_f16 support · llvm/llvm-project@1e9eae9 ↩︎