2020/11/05 には Zen 3アーキテクチャ を採用する Ryzen 5000シリーズ のレビューが各メディアより公開され、2020/11/06 には発売が開始された。
同時に Zen 3アーキテクチャ の詳細も公開され、「Software Optimization Guide for the AMD Family 19h Processors」 も AMD より公開されている。
Tech Docs | AMD
ただ Family 19h / Zen 3アーキテクチャ 単体の詳細であり、Zen 2アーキテクチャ との比較や、各改良点にどれだけ効果があるのか等は資料中では触れられていない。
Index
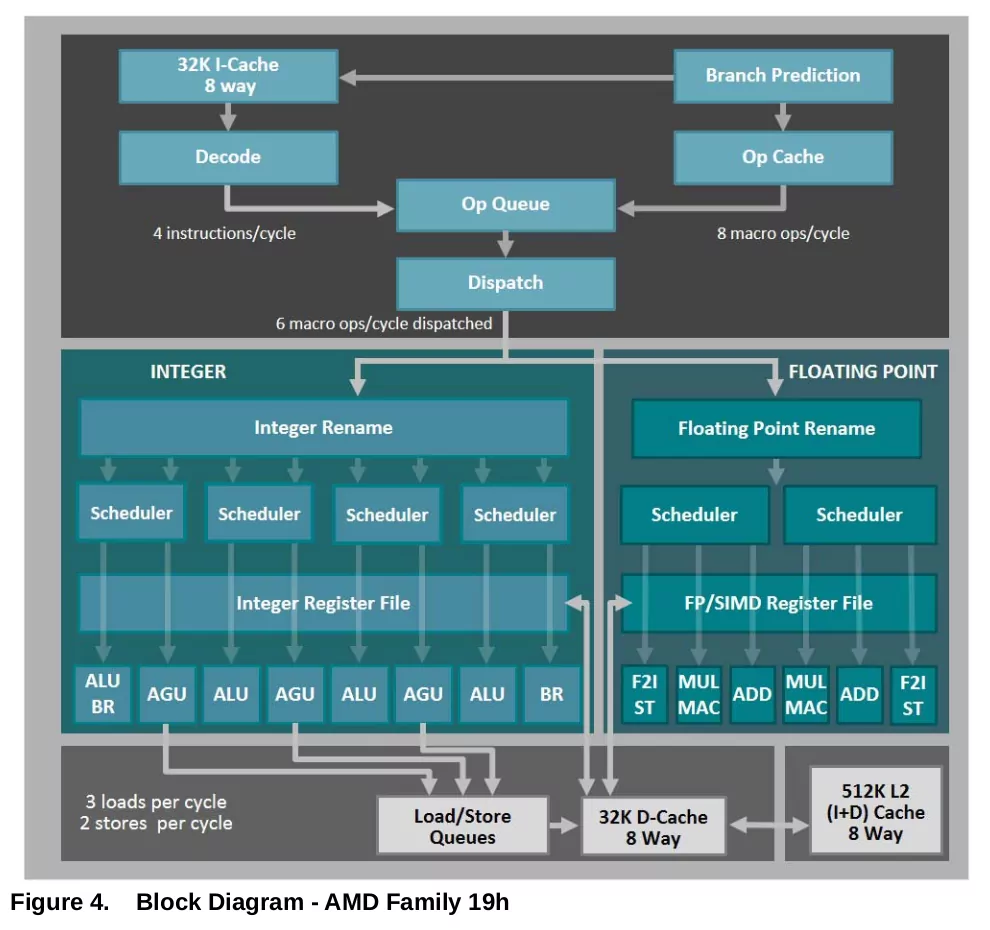
Family 19h Block Diagram
画像出典: Software Optimization Guide for the AMD Family 19h Processors
Zen 3アーキテクチャ
ダイ構成
メモリコントローラーや PCIe、SATA等の各 I/O のコントローラーや PHY (物理層) が搭載されている IOD は Ryzen 3000シリーズ から変わらず、CPUコアが搭載されている CCD との接続幅も、Write: 16-Byte/Cycle、Read: 32-Byte/Cycle と変わらない。
しかし、CCX のレイアウトが変更され、CPU 8-Core と L3キャッシュ 32MB で構成されるようになったため、CCX 間で通信するために IOD を経由することは減ったと思われる。同時に、レイテンシも大きく削減された。
キャッシュ構成
コアごとに持つ、L1データ/命令キャッシュ、L2キャッシュは Zen 2アーキテクチャ から変わらず、
L1データ/命令キャッシュは 32KB 8-way構成、L2キャッシュは 512KB 8-way 構成となっている。
L3キャッシュは Vermeer /Ryzen 5000シリーズ では CCX あたり 実質 CCD あたり
32MB を搭載し、これが最大容量となるが、16MB の構成も可能となっている。
16MB構成は、CPU に Zen 3アーキテクチャ を採用する Cezanne APU あたりが選択するではないかと思われる。
L3キャッシュ自体の構成は 16-wayセットアソシアティブとなっており、ここは Zen/2 アーキテクチャ から変わらない。
フロントエンド
フロントエンド部では、公式発表された時はデコード幅や Opキャッシュ容量、Opキャッシュから送り込む命令数、各スケジューラー (Int/FP) にディスパッチするマイクロOp数を増やしているのではないかと推測したが、1
実際はこれらの部分は Zen 2アーキテクチャ から拡張されておらず、サイクルあたりの x86デコード幅は 4命令、Opキャッシュからは 8命令、ディスパッチ可能なマイクロOp数は 6命令となり、Opキャッシュ容量は 4K となる。
これらを Zen 2アーキテクチャ から増やすのは、製造プロセスが同じままではトランジスタ効率、または電力効率の面でデメリットがあったのだろうか。
L1 BTB (Branch Target Buffer) のエントリ数は Zen 2アーキテクチャ から倍の 1024エントリとなる。
Zen アーキテクチャ では 256エントリ、Zen 2アーキテクチャ では 512エントリであったから、L1 BTB はアーキテクチャの世代を経るごとに倍に増やされていることになる。
ただ L2 BTB は 6656エントリと、Zen 2アーキテクチャ の 7168エントリから若干減っている。
| BTB (entries) | Zen | Zen 2 | Zen 3 |
|---|---|---|---|
| L0 BTB | 8 | 16 | 16? |
| L1 BTB | 256 | 512 | 1024 |
| L2 BTB | 4096 | 7168 | 6656 |
また、Opキャッシュのフェッチ高速化、きめ細かい 命令キャッシュとOpキャッシュパイプとの切り替え、Zero Bubble 分岐予測の導入などがあるが、それ以上の詳細は不明。
整数/Integer
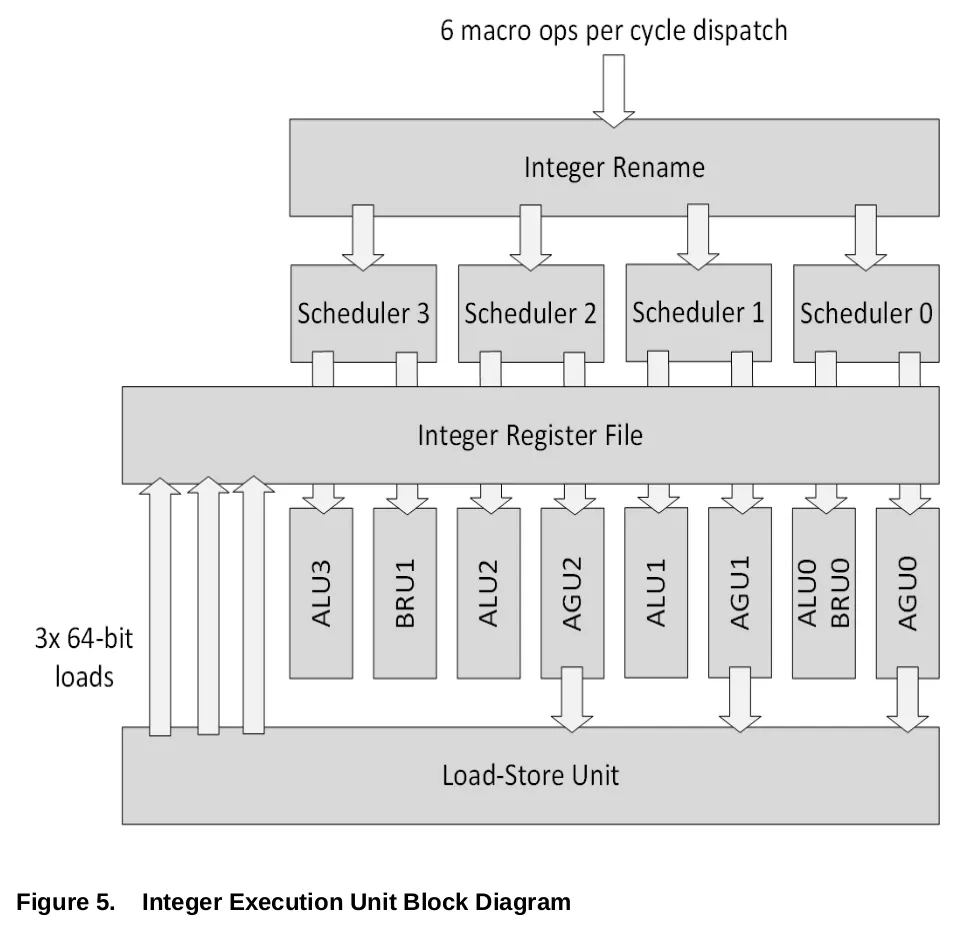
Family 19h, Integer Unit Block Diagram
画像出典: Software Optimization Guide for the AMD Family 19h Processors
Zen アーキテクチャ では、各整数演算ユニット (ALU)、AGU にスケジューラーが存在し、Zen 2アーキテクチャ では AGU が 3基に増えたことを受け、2つのマイクロOp を受け取ることが可能なスケジューラーを 3基で共有していた。
Zen 3アーキテクチャ ではスケジューラーが 4基となり、それぞれに ALU、AGU、独立した BRU (Brach Execution Unit) らが配置されるようになった。
各スケジューラーは最大 2つのマイクロOp を受け取ることができる。
4x ALU、3x AGU という数自体は Zen 2アーキテクチャ から変わらないが、BRU が独立したことで 8-way 構成となる。
また、Zen/2アーキテクチャ ではマイクロコード実装されていたがために遅く、処理に膨大サイクル数が掛かっていた PDEP/PEXT 命令に、Zen 3アーキテクチャ では ALU がネイティブで対応したため、3サイクルで処理できるようになった。
Load/Store
Load/Store を発行する AGU (Address Generation Unit) は Zen 2アーキテクチャ から変わらず 3基のままだが、サイクルあたりの Load/Store幅は拡張された。
Zen 2アーキテクチャ ではサイクルあたり 256-bit幅の 2x Loads、1x Store となっていたのが、
Zen 3アーキテクチャ ではサイクルあたり 最大で 3x Loads、または 2x Store となった。また、2x 128-bit か 1x 256-bit を個別にロードすることが可能となった。また、3基の AGU は対称で、全てが Load/Store キュー、L1/L2 TLB にアクセス可能。
最大で 2x Store を発行することが可能だが、データ幅が 128-bit または 256-bit の場合は最大 1つまでとなる。
Load/Store は Zen 2アーキテクチャ から、より柔軟に扱えるよう拡張したと言える。
浮動小数点/Floating-Point
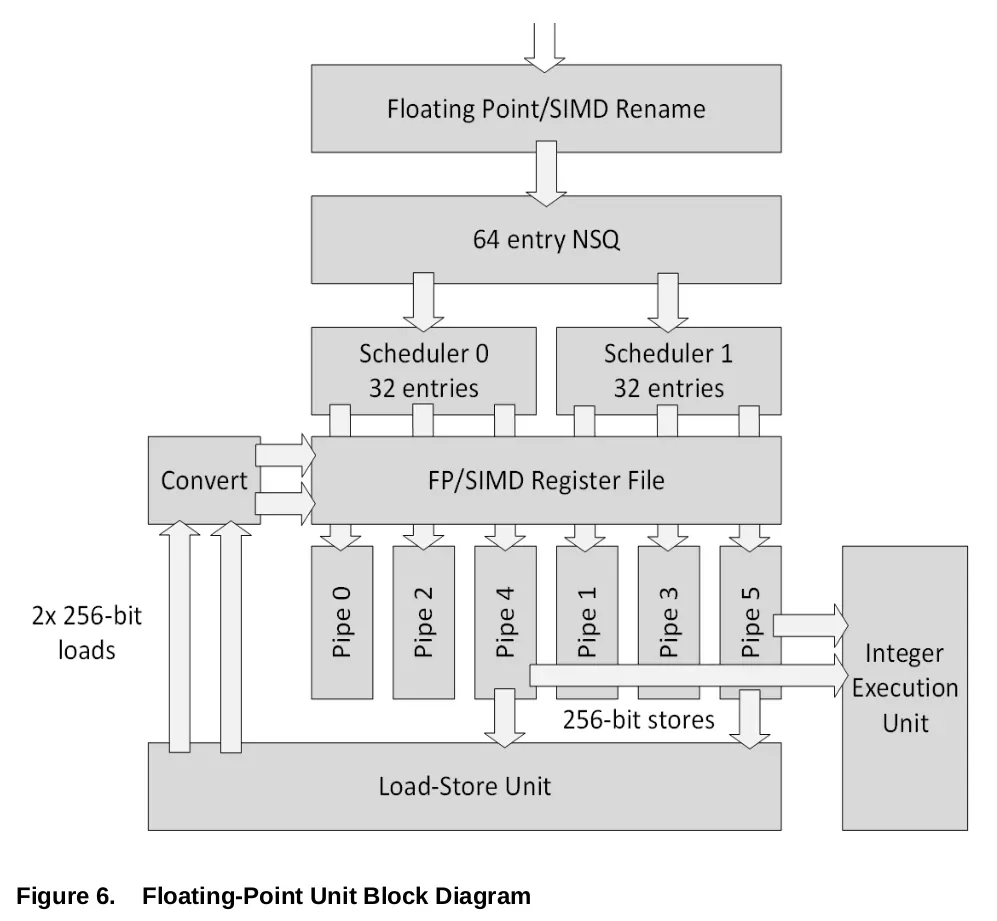
Family 19h, Floating-Point Unit Block Diagram
画像出典: Software Optimization Guide for the AMD Family 19h Processors
FP側はスケジューラーを 2基持ち、それぞれ SQ (Scheduler Queue) を 32エントリを保持する。Zen/2アーキテクチャ では 1基のスケジューラーに SQ を 36エントリ保持する構成であった。
そして各パイプ/実行ユニットは、2基のスケジューラーが対称となるように配置されている。
FPユニットは Load/Storeユニットからサイクルあたり最大 256-bit のロードを受け取ることができる。
Store処理と、FPレジスタから汎用レジスタへのデータ転送を行なう専用のパイプが 2本用意されているが (Pipe 4,5) 、スループットとしてはサイクルあたり 1つに制限されている。
Zen 3アーキテクチャ では FMA命令の処理の掛かるサイクルが Zen 2アーキテクチャ から 1サイクル短縮され、4サイクルで処理が可能となった。
また、新規に VAES (Vector AES) 命令に対応した。
VAES (Vector AES) は AES暗号化のエンコード/デコードをベクトルで実行する命令であり、Intel CPU では Sunny Cove (Ice Lake Client/Server) からサポートされている。
VAES に対応するソフトウェアには、オープンソースで開発される圧縮/展開ソフト、7-zip があり、Zen 3アーキテクチャ ではこのソフトの実行性能が向上しているものと思われる。