Index
非対称な Shader Array 構成の効率を向上させる
まず AMD GPU のアーキテクチャでは、GPU のコア部と言える、シェーダーを処理する CU、Rastrizerユニット、Primitiveユニット、RenderBackendユニット等を、Shader Engine としてまとめて管理している。
そして、RDNAアーキテクチャ では Shader Engine 内部が、それぞれ L1メモリキャッシュ (128KB) を持つ Shader Array 2基にコア部を分け、構成されている。
また、CU は 2基をまとめた Dual Compute Unit / WGP(Work Group Processor) 単位となる。
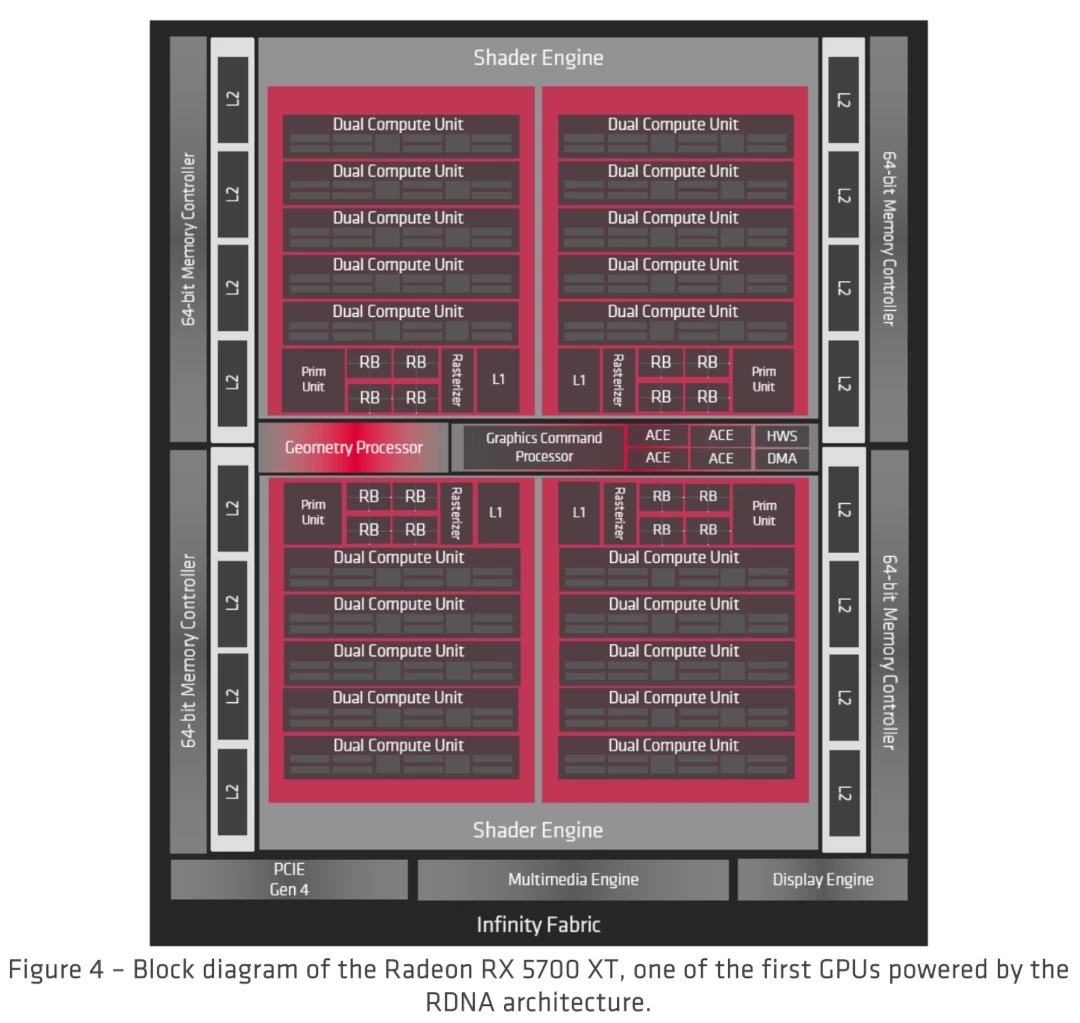
Navi10 Diagram
画像出典: https://www.amd.com/system/files/documents/rdna-whitepaper.pdf
AMD GPU は Shader Engine ごとに Workload Manager を持ち、各 Shader Engine の規模は対称となるように設定されるが、Shader Engine 内部の Shader Array については規模が異なる場合がある。
例えば、RDNAアーキテクチャ である RX 5700 は Compute Unit を 36基持つ。
RX 5700 のベースとなる GPU ASIC Navi10 は Shader Engine 2基、その内部の Shader Array 2基で構成されており、Shader Array は 5WGP(10CU) の規模となる。
Shader Engine 2基は規模が対称となるため、それぞれ CU を 9基持つことになるが、その場合内部の Shader Array の構成は 4基と 5基のものに分かれ、非対称となる。
上記パッチはこの Shader Array が非対称の場合に向けたもので、Pixel Shader を処理する際の無駄を減らす目的がある。
ハードウェアは Pixel Shader を処理する Wave(スレッドの塊) を各 Shader Array に同じ数発行するが、Shader Array あたりの CU数が非対称だと、規模が小さい方に処理速度が引っ張られて効率が悪化する。
そこで、小さい方の CU数に合わせて Wave を発行することで効率の悪化を防ぐ。
大きい方の Shader Array では処理に関係しない、余分な CU が出てくるが、その分消費電力を減らすことができ、稼働させる CU のクロックの引き上げに回すこともできる。
効率がそこまで向上しない場合もあるのか、将来的には特定のアプリケーション向けに有効無効を設定するかもしれない、とされている。
例に上げたように、RX 5700 等 RDNA /GFX10 世代でも Shader Array が非対称となる GPU があるが、機能は現状 RDNA 2 /GFX10.3 世代にのみ有効可能となっている。
RDNA 2 /GFX10.3 で、電力管理またはハードウェアスケジューラの改良が行なわれたのかもしれない。
gpu_info ファームウェアは必要無し
Vega /GFX9 世代から導入された1、GPU ASIC の情報を保存する gpu_info ファームウェアだが、RDNA 2/GFX10.3 世代の GPU Sienna Cichlid 、Navy Flounder では必要無いという。
[PATCH] drm/amdgpu: remove gpu_info fw support for sienna_cichlid etc.
discovery binary からの情報で十分というのが理由らしいが、discovery binary が何を指すのかは不明。VBIOS あたりだとは思うが。
Sienna Cichlid 、Navy Flounder の gpu_info ファームウェアは既に ROCm のパッケージや Linux向けProドライバー等に含まれていたが、これらはどれだけ実物の GPU ASIC を反映していたのだろうか。
Xbox Series S
Microsoft より Xbox Series X と同世代かつ小型な Xbox Series S が発表された。
CPU は XSX と同じ Zen 2コア を 8基搭載しているが、クロックが 0.2GHz程低くなっている。
GPU は大きく規模を削られ、XSX の 52CU@1.825GH に対し XSS は 20CU@1.565GHz となり、ピーク演算性能では 4TFLOPS と 1/3 である。メモリも GDDR6 16GB 320-bit に対し GDDR6 10GB 128-bit。
メモリバス幅が 128-bit、メモリ容量は 10GB というのは、単純に 16Gb(2GB) * 4 で考えても一致しないが、1* 32-bit を 2* 16-bit に分け、そこに 16Gb(2Gb) * 2 を接続しているのかもしれない。
SoC のダイサイズは、XSX が 360.45mm2、XSS は 197.05mm2と、半分より少し大きいサイズとなっている。
今は削除されてしまっているが
あるニュース系サイトで XSS Soc のチップ写真が掲載されたスライドが公開されており、見た限り、XSS SoC は 24CU 持つが、XSX 同様に 4CU を冗長ユニットとし、20CU を製品仕様にしているようだ。
また、XSX は 2-ShaderEngine の構成だったが、XSS では 1-ShaderEngine であるように見えた。
| Xbox Series X | Xbox Series S | Navi10 | Navi14 | |
|---|---|---|---|---|
| SE (Shader Engine) |
2 | 1? | 2 | 1 |
| SH per SE | 2 | 2 | 2 | 2 |
| WGP(CU) per SH | 7(14) | 6?(12?) | 5(10) | 6(12) |
| Total WGP(CU) | 28(56) | 12?(24?) | 20(40) | 12(24) |