いつかやろうと思っていて放置していたVega10、Vega20のユニット推測を、毎度お馴染みFritzchens Fritz | Flickr氏によるダイショットを元に行なった。
Vega10
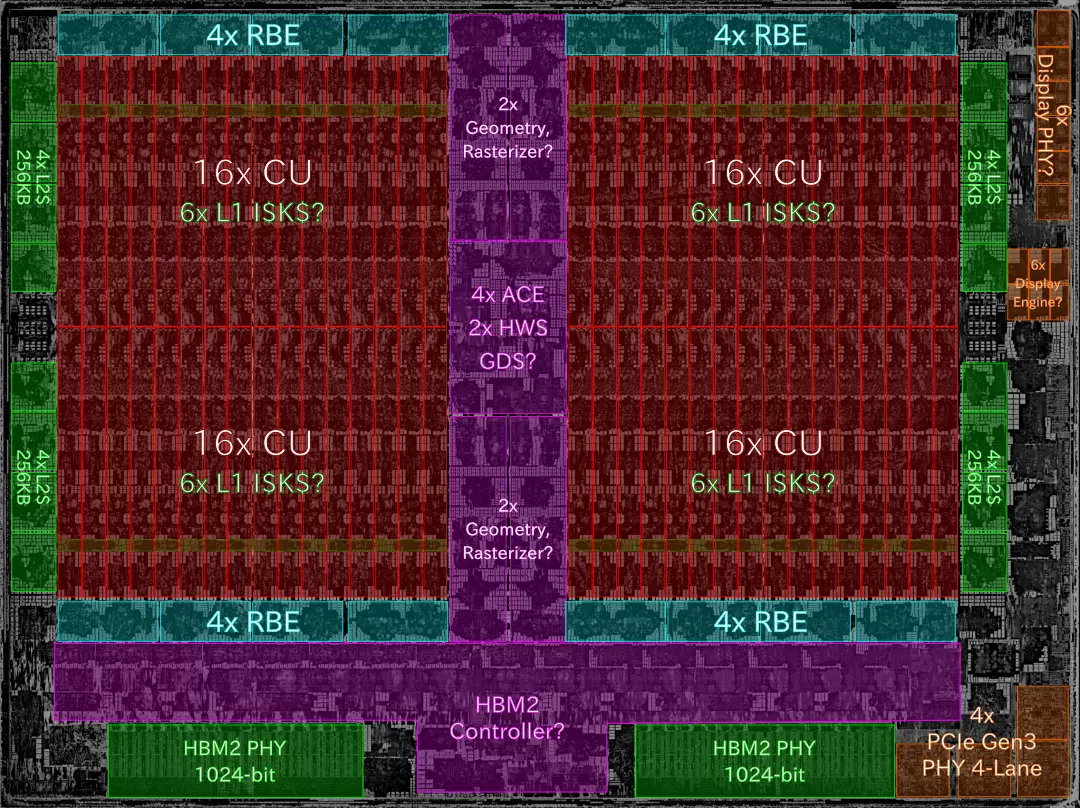
Vega10 推測
ダイサイズ: 509.73mm2
画像出典: AMD@14nm@GCN\_5th\_gen@Vega10@Radeon\_RX\_Vega\_64@ES-Sample@\_\_… | Flickr
元画像は色付きであり、そのままだと字が非常に読みにくくなるため画像に補正を掛けた。それでもまだぼやけて分かりにくい所があるが。
GPUOpen-Drivers/pal: Platform Abstraction Libraryからの情報では1、
- 4-ShaderEngine
- ShaderEngineあたりのRBE (RenderBackend) 数は4基
- 〃 のCU (ComputerUnit) 数は16基
- TCC (L2 cache) ブロック数は16基 (ブロックあたり256KB、計4MB)
RadeonFeatureからの情報では、
- Display Controller数は6基
となっており、ダイショットを元にした推測も基本それに沿っている。
見にくくなってしまったが、右上 6基が Display PHY/Interface 、その下の6基が Display Engien としている。
疑問点
AMD GCNアーキテクチャでは、最大4CUで I$(Instruction Cache) 32KB と K$(Scalar Cache) 16KBを共有している。
Vega10 では ShaderEngineあたり16CUということから、最大の4CUで共有し、I$K$のブロックは計4基となるはずだが2、
ダイショットでは6基あるように見えた。
単なら私の見間違い、勘違いか、歩留まり向上策の1つか。
それと Geometry Processor と HBM2 Controller の間にバッファかキャッシュらしきユニットがあるが、正体は不明。
HBM2 Controller がある反対側にもあるため、それのバッファとは違うように思う。
近くに配置されている RBE か Geometry Processor に関連した、ラスタライザ系のユニットだったりするのだろうか?
Vega20

Vega20 推測
ダイサイズ: 330.93mm2
画像出典: AMD@7nm@GCN\_5th\_gen@Vega20@Radeon\_VII@\_-\_@\_\_\_DSCx2\_polysil… | Flickr
GPUOpen-Drivers/pal: Platform Abstraction Libraryからの情報では Vega10 と特に変わらず、3
- 4-ShaderEngine
- ShaderEngineあたりのRBE (RenderBackend) 数は4基
- 〃 のCU (ComputerUnit) 数は16基
- TCC (L2 cache) ブロック数は16基 (ブロックあたり256KB、計4MB)
RadeonFeatureからの情報ではこちらも、
- Display Controller数は6基
となっており、ダイショットを元にした推測も基本それに沿っている。
推測をしている中で気付いたが、GPUのコア部、ShadeEngine内の配置はまったく Vega10 と同じだった。I$K$ が6基あるように見える点も。
そういった発見があるからダイショットを眺めるのは楽しい。
感想としては、Vega10 と比べてコア部こそ微細化の効果が見られるが、他GPUと接続するための Infinity Fabric (XGMI) 、さらに HBM2 2スタック分のインターフェース追加等、主に微細化が効きにくい I/O のパッド部にダイサイズが引っ張られて大きくなっているように感じた。
Navi10 のダイショットからはCUからWGPへの基本単位変更もあり、Vega20 よりも詰めている印象を受ける。
Navi10のダイ観察 & 推測 | Coelacanth’s Dream
設計の最適化に掛けた時間にも結構な違いがあったりするのだろうか?
Vega10とVega20の比較

L: Vega10 / R: Vega20
Process: GF 14nm / TSMC 7nm (N7)
DieSize: 509.73mm2 / 330.93mm2
CU Size(推定): 3.744mm2 / 1.592mm2
Vega20 のShaderEngineのサイズが Vega10 のほぼ半分になっているところに、TSMC 7nm(N7)移行の効果が見て取れる。
CUのサイズもほぼ半分となっていた。
それに対し、画像を見てもわかりやすいが、HBM2 PHY 、PCIeGen4 4-Lane PHY 等、I/Oの物理層となる部はほとんどサイズが変わっていない。
-
https://github.com/GPUOpen-Drivers/pal/blob/e642f608a62887d40d1f25509d2951a4a3576985/src/core/os/nullDevice/ndDevice.cpp#L835 ↩︎
-
https://gpuopen.com/wp-content/uploads/2019/08/RDNA_Architecture_public.pdf#page=27 ↩︎
-
https://github.com/GPUOpen-Drivers/pal/blob/e642f608a62887d40d1f25509d2951a4a3576985/src/core/os/nullDevice/ndDevice.cpp#L871 ↩︎