企業が公式的にハードウェアの詳細を語ってくれるイベント Hot Chips。ハードウェアオタクからしたら最高なのは間違いないが、自分が語れることはそうない。
メンバー登録(有料)をしていないから画像はどっかから引用・拝借するしかないし、発表の動画、スライドがパブリックになるまでには数ヶ月掛かる。
それに何よりも日本で活躍するテクニカルライター方々が魅力的に解説してくれるから、自分が積極的に語る必要もない。自分にとって記事を書くこと自体はハードウェア購入資金にはなってくれない。
そういう訳で、以下個人的なメモ・補足・疑問点・まとめ。
Xbox Series X
Hot Chips 2020 Live Blog: Microsoft Xbox Series X System Architecture (6:00pm PT)
Microsoft が Zen 2 + RDNA 2 を搭載する次世代ゲーム機 SoC の概要を発表。
製造プロセスは TSMC N7 Enhanced と少しぼかされたが、ダイサイズは 360.4mm2。トランジスタ数は 15.3B。
L2キャッシュは 5MB(5120KB)で、対応するメモリチャネル数は 20本であるから、各L2キャッシュブロックの容量は 256KB と、Navi10 /Navi14 等と同様の規模となっている。
RDNA Whitepaperでは 64KB-512KB の範囲内で設定可能とあるが、Xbox Series X SoC の設計でその点を変えることはしなかったようだ。
WGP数は 26基(=CU 52基)で、2基を無効化することで製品としている。 全体的には 2-ShaderEngine、4-ShaderArray という構成であり、ShaderArray あたりの WGP数は 7基となる。
WGPの内部構成、そして レイ計算ユニットの概要が明かされており、TMU(Texture Mapping Unit) と切り替えて使う方式のようだ。
少しの(Minor) ダイエリアコストで 3~10倍のアクセラレーションを可能としており、TMU との切り替えであれば、レイトレーシングを採用していないゲームにおいて無駄になるユニット・ダイエリアを少ないものに抑えられる。
気になるのは兼用による、レイトレーシング有効時と無効時の性能差だが、さすがにそこまでは明かされていない。
ごく小さい(Very small) ダイエリアコストで、テクスチャーを解像度に最適化する MIP maps を効率的に行なう Sampler Feedback Streaming を導入しており、これによって最大 60% の I/O を減らせるとしている。
ゲームにも使われるような機械学習の推論でも、ごく小さいダイエリアコストで 3~10倍の性能向上を達成している。
性能に関しては何との比較かが不明だが、性能向上の中身は Navi12 /Navi14 も対応している混合積演算命令ではないかと思う。
それらは 8個の INT4 をまとめて(パックド) 計算する命令に対応している。
コストの小ささから特別ユニットを搭載したものではないだろう。
GPUクロックは、FP32でのピーク性能は 12TFLOPS ということから、約1.8GHzと割り出せる。
また 116 Gpix/sec から、RenderBackend数は 16基(ROP 64基相当)と分かる。
それとダイサイズに関して、スライドに掲載されているダイショットを元にした計算では縦と横の長さは 縦: 約16.34mm、横: 約22.05mm となった。(微妙に合ってない)
それでもそこから、さらに L2キャッシュを除いた CPUコアと L3キャッシュ(4MB) のダイエリアを求めると、CPUコアは 約2.59mm2、L3キャッシュ(4MB) は 約4.53mm2と出た。
Zen系APU (Raven, Raven2, Renoir)と比較した表が以下となる。
| RavenRidge | Raven2 | Renoir | XSX SoC | |
|---|---|---|---|---|
| Process | 14nm | 14nm | 7nm | 7nm Enhanced |
| Die Size | 208.84mm2 | 148.55mm2 | 155.01.mm2 | 360.4mm2 |
| CPU Arch | Zen | Zen | Zen 2 | Zen 2 |
| CPU Core Area (non include L2$) |
5.18mm2 | 5.18mm2 | 2.73mm2 | 2.59mm2? |
| Total CPU L3$ | 4MB | 4MB | 8MB | 8MB |
| L3$ (4MB) Area | 10.91mm2 | 10.91mm2 | 5.39mm2 | 4.53mm2? |
Renoir と比較して、CPUコアは 約94%、L3キャッシュ(4MB) は 約84%のダイエリアとなっており、確かに 7nm Enhanced であるように見える。
Xe-LPアーキテクチャ
Hot Chips 2020 Live Blog: Intel’s Xe GPU Architecture (5:30pm PT)
Architecture Day 2020 でも Xe-LPアーキテクチャの詳細は発表されていたが、
Intel Architecture Day 2020 個人的まとめ ―― XeHP は 1-Tile 512EU、XeLPアーキテクチャ詳細 | Coelacanth’s Dream
今回は Xe共通の部分も一部解説されており、任意で追加されるユニットとして、FP64 と Matrix Extension (XMX) をあげている。
恐らく 2つは Xe-HPCに向けたもので、後者は Intel 次世代サーバー向けプロセッサ Sapphire Rapids が対応するアクセラレーター向け命令 AMX(Advanced Matrix Extension) と連携するためのユニットとされる。1
他は Xe-HP が HBM2e を採用することが明言されたくらい?
Ice Lake (Server)
Ice Lake (Client) も Sunny Cove コアではあるが、AVX-512 の実行は Port 0 のみとなっており、
Ice Lake (Server) は Port 0 と Port 1 を束ねての実行と、Port 5 での実行が可能となっている。
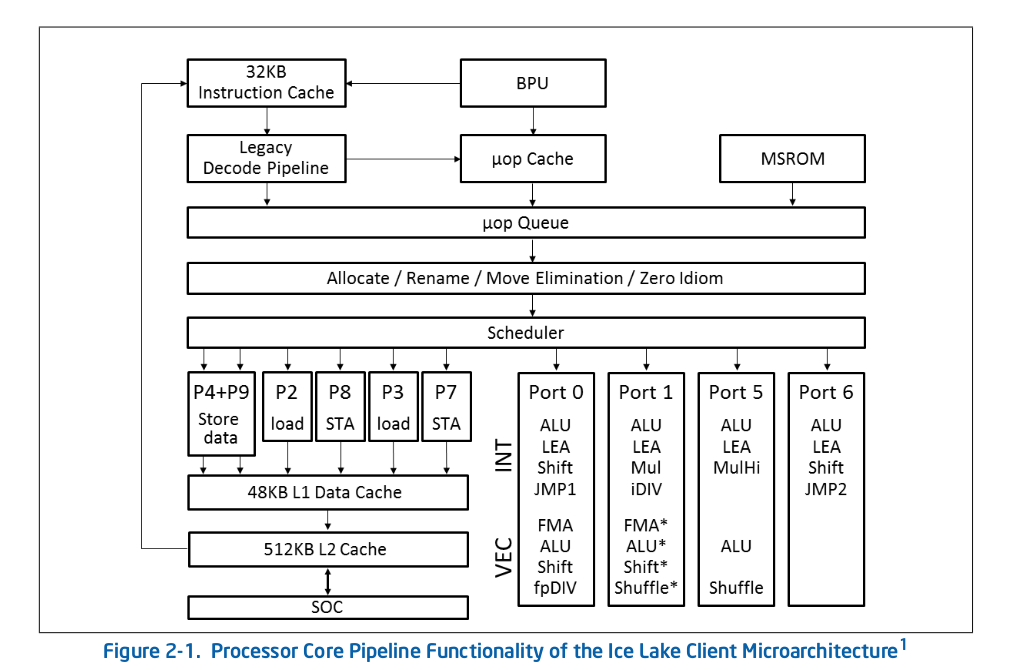
Ice Lake (Client) Microarchitecture
画像出典: Intel® 64 and IA-32 Architectures Optimization Reference Manual