以前の Geekbench実行結果から、キャッシュ構成は Ice Lake (Client) 同様と判明していた Rocket Lake だが、エンジニアサンプリングであろうプロセッサの Linux Kernel が表示するメッセージ dmesg から、AVX-512 命令に対応することが判明した。
[ 0.000000] x86/fpu: Supporting XSAVE feature 0x020: 'AVX-512 opmask' [ 0.000000] x86/fpu: Supporting XSAVE feature 0x040: 'AVX-512 Hi256' [ 0.000000] x86/fpu: Supporting XSAVE feature 0x080: 'AVX-512 ZMM_Hi256' ~~~ [ 0.000000] DMI: Intel Corporation Rocket Lake Client Platform/RocketLake S UDIMM 6L RVP, BIOS RKLSFWI1.R00.1205.A00.2005152058 05/15/2020 ~~~ [ 0.080759] smpboot: CPU0: Genuine Intel(R) 0000 @ 3.20GHz (family: 0x6, model: 0xa7, stepping: 0x0) ~~~ [ 0.097075] smpboot: Total of 16 processors activated (102144.00 BogoMIPS)引用元: [Bug][RKL]FW load failed · Issue #3173 · thesofproject/sofL
> https://github.com/thesofproject/sof/files/4917659/dmesg.txt
情報元は thesofproject/sof: Sound Open Firmware であり、Sound Open Firmware は Intelプロセッサやそれとペアになる PCH に内蔵される音声処理用のDSPのサポートを提供するため、Intel がオープンソースで開発しているプロジェクトである。1
上記 dmesg のログもバグ報告のためアップロードされたもの。
今回の Rocket Lake プロセッサの仕様は、16-Thread、Base Clock 3.2GHz、ステッピングは 0x0 と、前回上げた Geekbench実行結果のものと一致する。
Intel Corporation Rocket Lake Client Platform - Geekbench Browser
しかし、dmesg ではベンチマーク実行結果よりも詳細な情報が表示されるため、前回ではわからなかった AVX-512 命令のサポートが判明した。
実装はどうなるか
前回行なった推測では、端的に言って、Skylake-SP の例から消費電力比性能が悪化してしまうため、Rocket Lake では AVX-512 をサポートしないのではないか、としたが、
今回明らかになった情報でそれは破れた。
しかし、実装が Ice Lake (Client) とまったく同じかはまだわからず、異なる可能性がある。
異なる実装方式で考えられるのは、SIMD演算器自体は 256-bit であり、AVX-512 を 2回に分けて実行するというものだ。
これはそれなりに見かける実装方法であり、例えば、AMD Zen アーキテクチャ は AVX2(256-bit) をサポートしていたが、SIMD演算器は 128-bit までであったし、Centaur CNS アーキテクチャ (CHA SoC) も AVX-512 をサポートするが SIMD演算器は 256-bit だった。
前2つの例とは少し異なるが、Intel Skylake-SP も Port 5 では AVX-512 を 1回で処理することができ、Port 0 と Port 1 はそれぞれ 256-bit だが束ねることで全体のスループット的には 2個の AVX-512 実行が可能なものとなっていた。
同様に、Rocket Lake も AVX-512 をサポートするが、演算器は 256-bit の実装に留め、2回に分けて実行、もしくはそれぞれ 256-bit の演算器を持つ 2つの実行ポートを束ねて実行する方式が考えられる。
この実装方式の利点としては、AVX-512 をサポートでき、それに必要とされる変更は主にベクトルレジスタの増量とアクセスポート部であるため、演算器も対応させる方式と比べて、割かなければならないリソース、ダイエリアはずっと小さくて済む。
欠点としては、若干でも必要とするリソースは増えるのに、ピーク性能は変わらないことがあげられるが、これに関してはサポートすることの意味が Intel にとっては大きいだろうから、あまり気にならないように思う。
Ice Lake (Client) のマイクロアーキテクチャは以下の画像の様になっており、AVX-512 を処理できるのは Port 0 のみである。
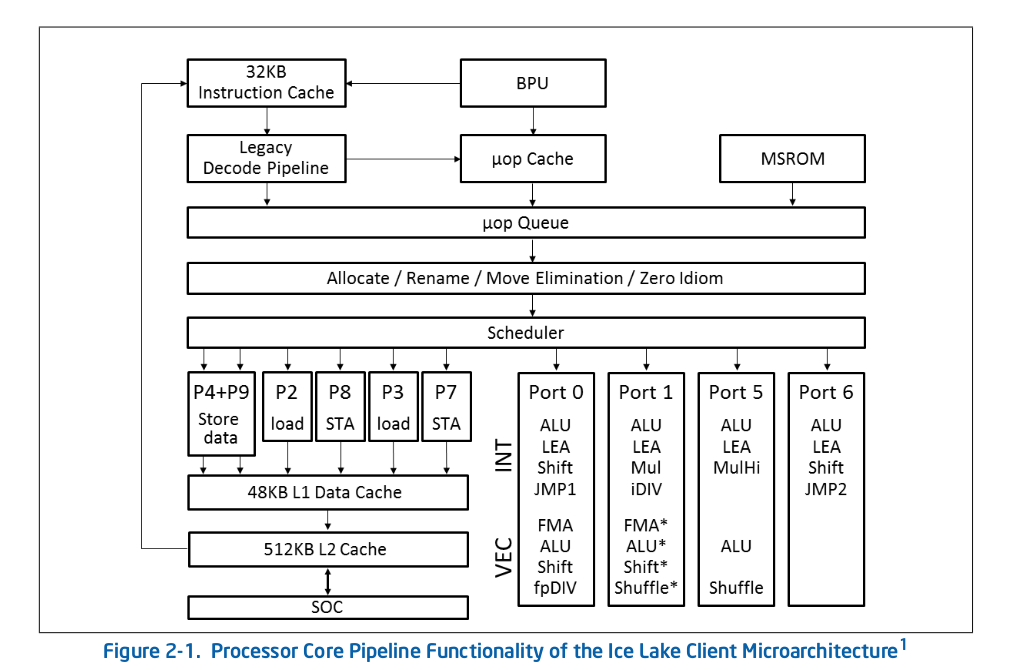
Ice Lake (Client) Microarchitecture
画像出典: Intel® 64 and IA-32 Architectures Optimization Reference Manual
Rocket Lake ではこの Port 0 と Port 1 を束ねて AVX-512 を実行する方式を取る かもしれない 。
そして気になるのは、2回に分ける、もしくは 2ポートを束ねる方式の場合、L1 Data Cache の帯域がどうなるかだが、Skylake (Server) アーキテクチャから、消費電力を抑えるため 96Byte/Cycle とすることが考えられる。
ただ、まあこれは推測よりも、自分の願望と言った方が近い気がする。
| Data Cache | Skylake (Client) | Skylake (Server) | Ice Lake (Client) | Rocket Lake |
|---|---|---|---|---|
| L1D$ Size | 32KB | 32KB | 48KB | 48KB |
| L1D$ Bandwidth (byte/cycle) |
96B (Load:2x32B) (Store:1x32B) |
192B (Load:2x64B?) (Store:1x64B?) |
192B (Load:2x64B) (Store:1x64B or 2x32B) |
96B??(guess) (Load:2x32B??) (Store:1x32B??) |
| L2$ Size | 256KB | 1024KB | 512KB | 512KB |
| L2$ Peak Bandwidth (byte/cycle) | 64B | 64B | 64B | 64B? |
| L3$ Size (per Core) | 2MB | 1.375MB | 2MB | 2MB |