かつてx86 CPU市場にてある程度の存在感を示していたVIA/Centaur Technologyが、新たに推論用のアクセラレーターを組み込んだサーバー向けCPUを発表し、話題になっていたが、
先日、Centaur Technologyが資料の一部公開とRedditのスレッドで質疑応答を行ない、より詳細が明らかになったため、紹介してみようと思い立った次第だ。
- x86 CPU Design House Centaur Technology will host an AMA next week, Thursday Jan 23, 2020 @ 12:00pm-3:00pm CST - r/hardware Reddit
- MPR Article Template - MPR_19_12_02_Centaur_Adds_AI_to_Server_Processor.pdf
- Centaur’s x86 SoC with AI Coprocessor Technology - PRSlides_1118_Release.pdf
ただ、最初に断りを入れさせていただくと、自分はテクニカルライターではなく、ブロガーと言うのも怪しい存在だ。
そのため、内容の正確性には責任を持てない。
知識が及ばない部分や、資料を読むのが一番だと判断した部分は意図的に飛ばしてもいる。
だが責任を完全に放棄した訳ではないため、間違っていた場合は連絡をくださると嬉しい。
解説にはWikiChipをオススメしたい。
- Centaur Unveils Its New Server-Class x86 Core: CNS; Adds AVX-512 | WikiChip Fuse
- Centaur New x86 Server Processor Packs an AI Punch | WikiChip Fuse
Table of Content
概略
名称は、SoC全体のコードネームがCHA、x86 CPU部のマイクロアーキテクチャ名がCNS、DLA(deep-learning accelarator)部がNcoreとされている。
製造プロセスはTSMC 16FFC。ダイサイズは194mm2。
CHAのx86 CPU 8コアはそれぞれL3キャッシュ 2MBを持つ。
CNSは前世代のCPUよりもはるかに高いIPCを目標に設計された。
クロックは2.5GHz。
Ncoreはデータ精度 INT8で20TOPS(trillion operations per second)のピーク性能。
NVIDIA Tensor CoreやIntel Spring Hillに見られる流行りのMACアレイではなく、SIMDエンジンで構成されるが、SIMD幅は極端に広く、4096-Byte(32,768-bit)を並列に処理できる。
NcoreアーキテクトであるGlenn Henry氏はこれを「AVX-32,768」に喩えており、これはIntelが推すAVX-512の64倍も広い。
これによりデータ精度 INT8で20TOPS(trillion operations per second)ものピーク性能を持つ。
大量のデータをSIMDユニットに供給するため、専用のSRAM 16MBが設けられている。
また2ソケットのシステムにも対応する。
ターゲットにはエッジサーバー、2ソケットシステムでは低コストのサーバーを想定している。
CNS (x86 CPU)
Centaur CNS microarchitecture
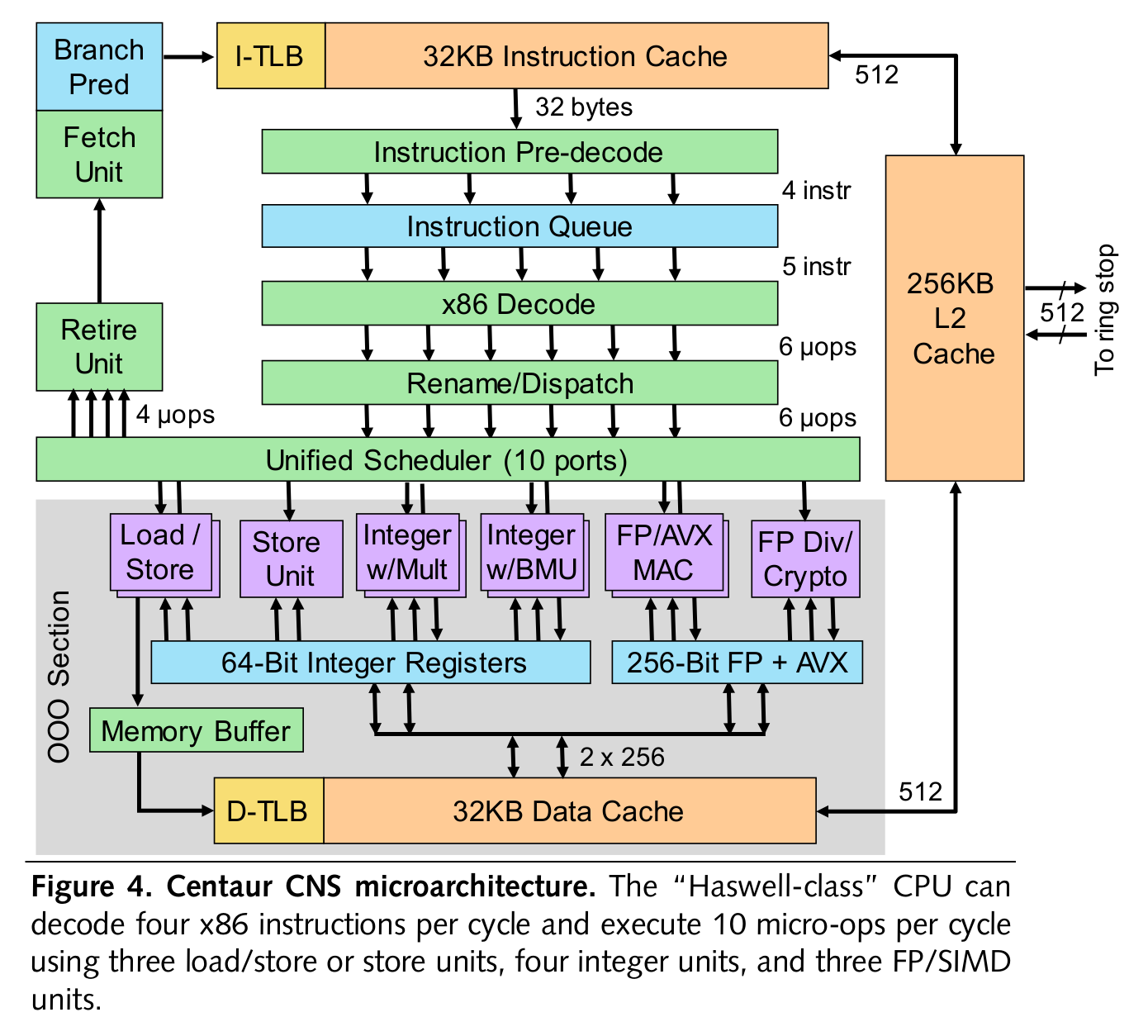
Centaur CNS microarchitecture
出典: MPR Article Template - MPR_19_12_02_Centaur_Adds_AI_to_Server_Processor.pdf
フロントエンド
前アーキテクチャである VIA Isaiah から大きな前進を果たしたとし、Isaishがピークで、
- サイクルあたり 3個 のx86命令デコード
- 7個 のmicro-opsをout-of-order実行
を可能だったのに対し、CNSはピークで、
- サイクルあたり 4個 のx86命令デコード
- 10個 のmicro-opsをout-of-order実行
が可能となり、他にも、リオーダーウィンドウの増量、分岐予測の精度向上、スケジューラーの強化、AVX /AVX2 /AVX-512 命令のサポート、DLA(Ncore)へデータを送るための独自命令の追加が施された。
資料中には特別記述されていないが、スケジューラーからリタイア(実行完了)可能なmicro-opsが、サイクルあたり3個から4個へ拡張されている。
流れとしては、まず分岐予測段で次の命令アドレスを定め、命令キャッシュから32 Byte分を取り込む。
次にプリデコーダーが命令の境界を決め、4個のx86命令を命令キューへ送る。
デコーダーは通常サイクルあたり4個のx86命令を処理できるのだが、特定の組み合わせに対しては同時に処理できるため、最大でサイクルあたり5個のx86命令デコードが行えるとされている。
そのため資料中にあるIntelのアーキテクチャと比較した表では、x86 Decodersの行が 4-5 instr という書き方となっている。
そしてデコーダーはそれらのx86命令ををmicro-opsへ変換する。
micro-opキャッシュを持たないが、これは設計スケジュールの考慮事項に基づいて追加しなかったとのことで、他の設計部分に比べると優先度が低かったのだろう。必要ないと考えている訳ではらしい。
micro-opキャッシュにヒットすれば、複雑なx86デコードをバイパスできるため、デコード性能の向上と消費電力の削減という2つのメリットを得られる。
持たないことがIntel、AMDのCPUと比較した時にどれくらいの差を生むかは気になるところだ。
Intel CoreアーキテクチャやAMD Zen/2アーキテクチャのようなSMT機能は搭載されておらず、コアあたり1スレッドとなる。
バックエンド
MAC(multiply-accumulate, 積和演算)ユニットを含んだFP/AVXユニットが2基、3基目のFP/AVXユニットは除算と暗号化(AES)アクセラレーションを担当する。
3基のFP/AVXユニットはAVX-512をサポートしているが、256-bit幅であるため、AVX-512命令は2個のmicro-opsに分解されて実行される。
FP/AVXユニットからは2つのリードポートがレジスタファイルにあるように見えるが、積和演算には3つのソースオペランドが必要なはずだ。
もしかしたらZenアーキテクチャのように、MACユニットを含まない3基目のポートを使用するのかもしれない。
ZENの4つの浮動小数点/SIMD演算ユニットは、それぞれ2つのレジスタリードポートを備える。1サイクルに、各ユニットで2つのソースオペランドのリードが可能だ。しかし積和算時には、3つのソースオペランドをリードする必要がある。
「積和算では、3つの(ソース)オペランドが必要だ。レジスタファイルから読み出す場合、リードポートが足りなくなる。そのため、ちょっとしたトリックを使っている。積和算時には、加算パイプからレジスタファイルリードポートを1つ借用している。積和算時には、加算ユニットは使っていないため、加算ユニット自体は空いている。しかし、加算ユニットにはレジスタリードポートが1つしか残らない。そのため、加算(の命令発行)はスケジューラがブロックする」(Mike Clark氏, Senior Fellow, AMD)
AVX-512のロードとストアはそれぞれ2つのmicro-opsに分解されるものの、L1 Data Cacheはサイクルあたり合計512-bitのデータを受け渡せるようになっており、将来FP/AVXユニットを512-bit幅へ拡張したりするのかもしれない。
そしてAVX-512命令は、x86コアがNcoreへ高速に読み書きを行なうのに活かされているとのこと。
インターコネクト
512-bit幅の2重リングバスの構成を取り、CPUは各コアL3 cache 2MBのスライスを経由してリングに接続される。
CPUのクロックと同じ速度であり、理論ピーク帯域は320 GB/s (2 * 32B(256b) * 2.5[GHz] = 320 [GB/s]) となるが、データの通過に複数サイクルを要するため、使用可能なスループットは半分以下に留まる。
アーキテクチャ比較
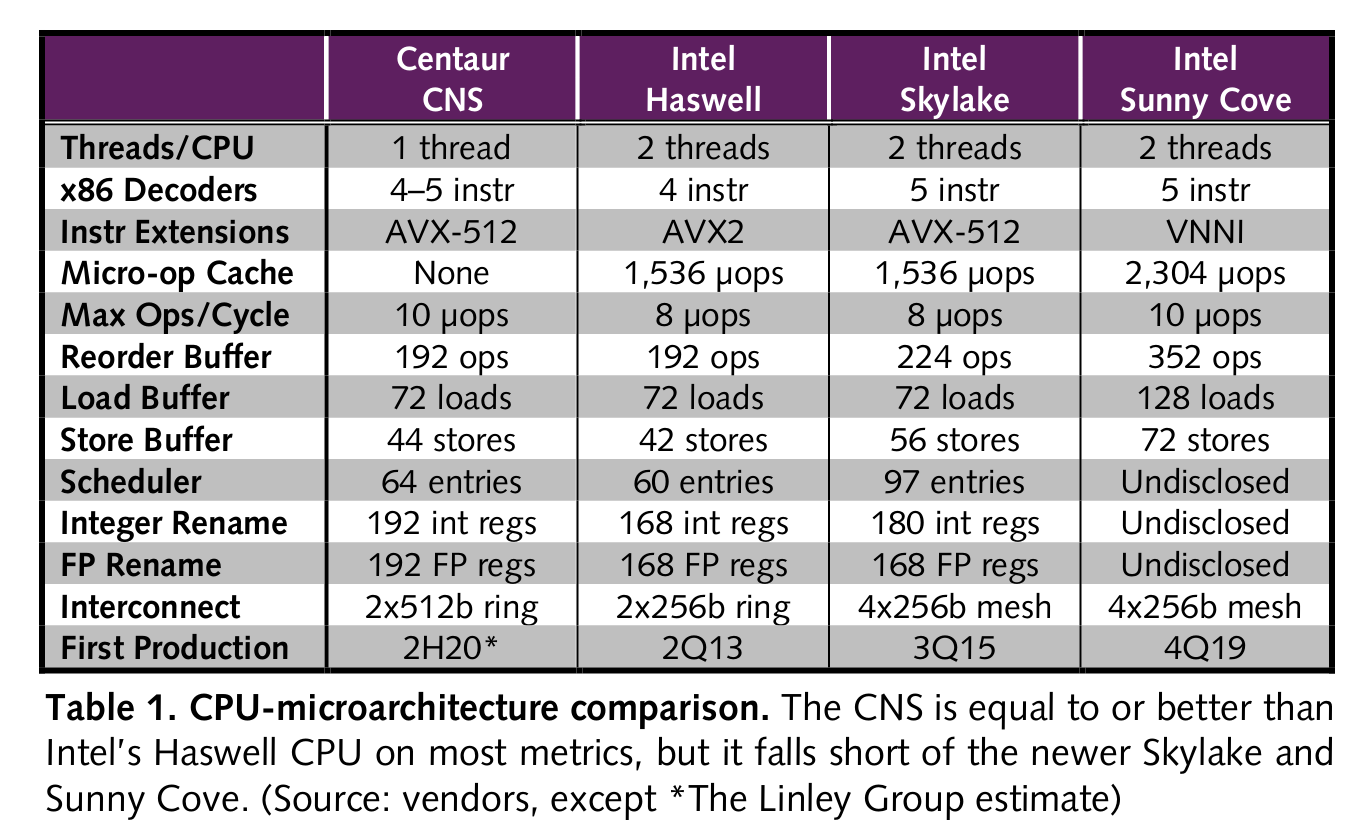
CPU-microarchitecture comparison
出典: MPR Article Template - MPR_19_12_02_Centaur_Adds_AI_to_Server_Processor.pdf
Zen/2 Architecture
Zen/2アーキテクチャをその表のフォーマットに合わせたものが以下となるが、Zen/2アーキテクチャは整数ユニットと浮動小数点ユニットでスケジューラーが分けられており、単純に比較は出来ないことを留意したい。| AMD Zen | AMD Zen2 | |
|---|---|---|
| Threads/CPU | 2 threads | 2 threads |
| x86 Decoders | 4 instr | 4 instr |
| Instr Extensions | AVX2 | AVX2 |
| Micro-op Cache | 2048 uops | 4096 uops |
| Max Ops/Cycle | 10 (6 int, 4 FP) | 10 (6 int, 4 FP) |
| Reorder Buffer | 192 uops | 224 uops |
| Load Buffer | 72 loads | 72 loads |
| Store Buffer | 44 stores | 48 stores |
| Integer Scheduler | 84 entries | 92 entries |
| FP Scheduler | 96 (NSQ+SQ) entries | 96 (64 NSQ + 36 SQ) entries |
| Interger Rename | 168 int regs | 180 int regs |
| FP Rename | 160 FP regs | 160 FP regs |
| Interconnect | 2x256b cross | 2x256b cross |
Centaurは客観的に、公正に見て、CHAをHaswellクラスの性能と評価している。
CHAはHaswellに対して、上記の表における数値の多くで同等以上を示し、特にRenameレジスタは多く、インターコネクトは広い。
しかし、CHAはSMT機能(Intelで言うHyper-Threading)とmicro-opキャッシュを持たない。
SMTはサーバーに求められる処理の多くで20-30%の性能向上が見込める。
micro-opキャッシュは上述したように、デコード性能の向上と消費電力の削減という2つの恩恵を受けられる。
Centaur CHAとIntelのプロセッサーとの大きな違いに、最大動作クロックもあげられる。
CHAが最大2.5GHzで動作するのに対し、IntelはSkylakeアーキテクチャ、14nm++プロセスにて最大5.0GHzが可能と、クロックでは倍も違うことになる。
ただサーバー向けでそこまでクロックを引き上げることはまず無く、消費電力効率も悪化するためXeonではクロックが抑えられており、Intelが持つアドバンテージは小さくなる。
結論として、CHAはローエンド帯のXeonと競合するとしている。
セキュリティ (Spectre, Meltdown)
言ってしまえば、不明。
ただ正式には公表されていないものの、過去のVIAプロセッサはSpectre、Meltdownの影響を受けるとされている。
Windows月例更新でVIAプロセッサにもSpectre/Meltdown対策が盛り込まれる - PC Watch
資料でもRedditのスレッド(後になってからだが質問をしたユーザーはいた)でも特に述べられていないことから、ハードウェアでの対策は施されていない可能性が高い。
余談だが、Centaur Technologyが設計した中国市場向けCPU、Zhaoxin(兆芯)は、
次世代の7-Seriesにて、SpsctreV2とSWAPGSの対策が施されている。
Zhaoxin 7-Series x86 CPUs Mitigated For Spectre V2 + SWAPGS - Phoronix
[PATCH] x86/speculation/spectre_v2: Exclude Zhaoxin CPUs from SPECTRE_V2 - Linux-Lernel Archive
このパッチを読む限り、x86 CPUでSpectreV2への対策が為されたのはZhaxin 7-Seriesが何気に初となるのだろうか。
AMDはZen2アーキテクチャでSpectre対策強化のため一部設計を変更したが、あくまで強化であり、ソフトウェア側(OS Kernel、ファームウェア)での対策が不要になる訳ではなかった。
- AMD、「Spectre」対策で次世代チップ「Zen 2」の設計を変更 - CNET Japan
- ASCII.jp:判明した第3世代Ryzenの内部構造を大解説 AMD CPUロードマップ (3/4)
Ncore
CHA die plot
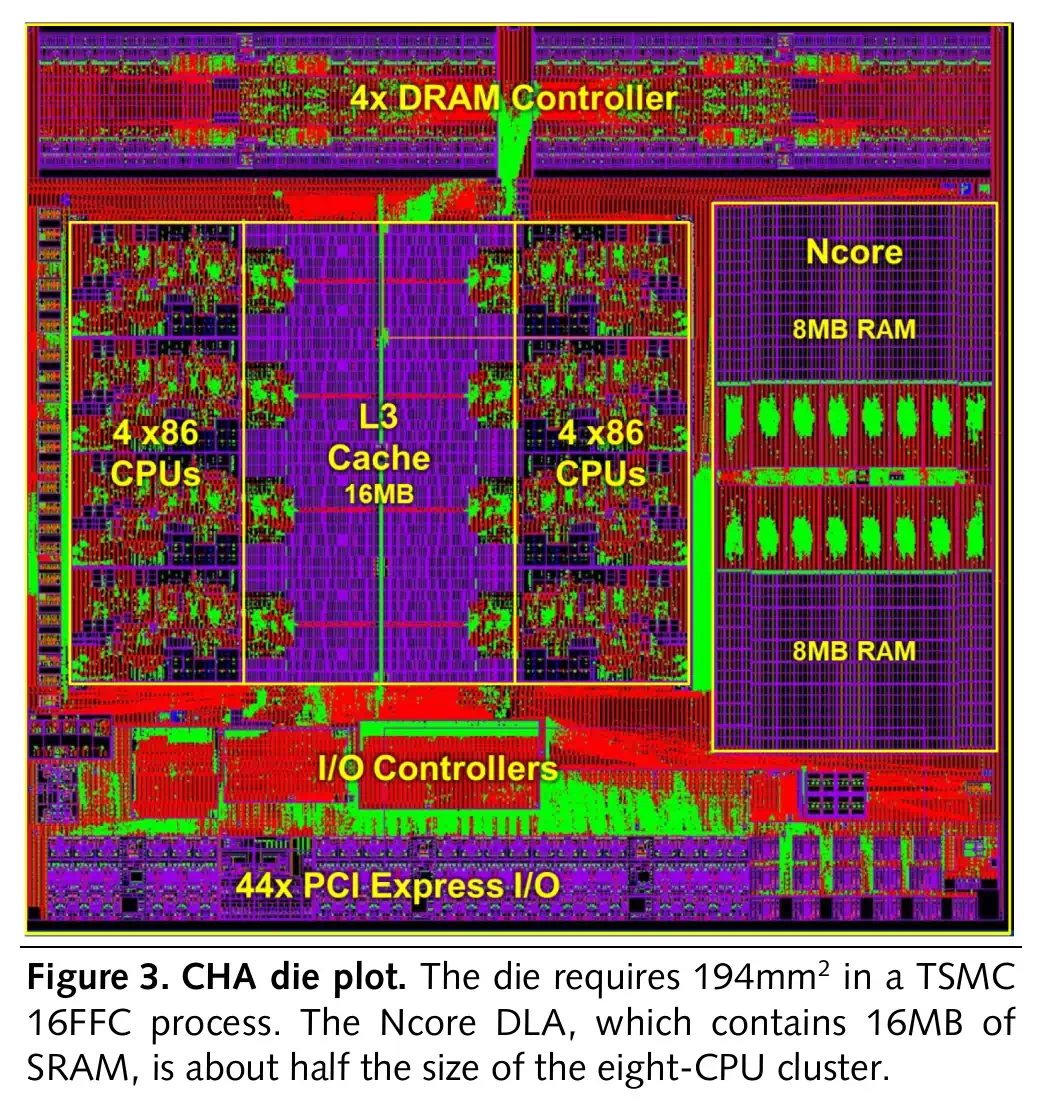
CHA die plot
出典: MPR Article Template - MPR_19_12_02_Centaur_Adds_AI_to_Server_Processor.pdf
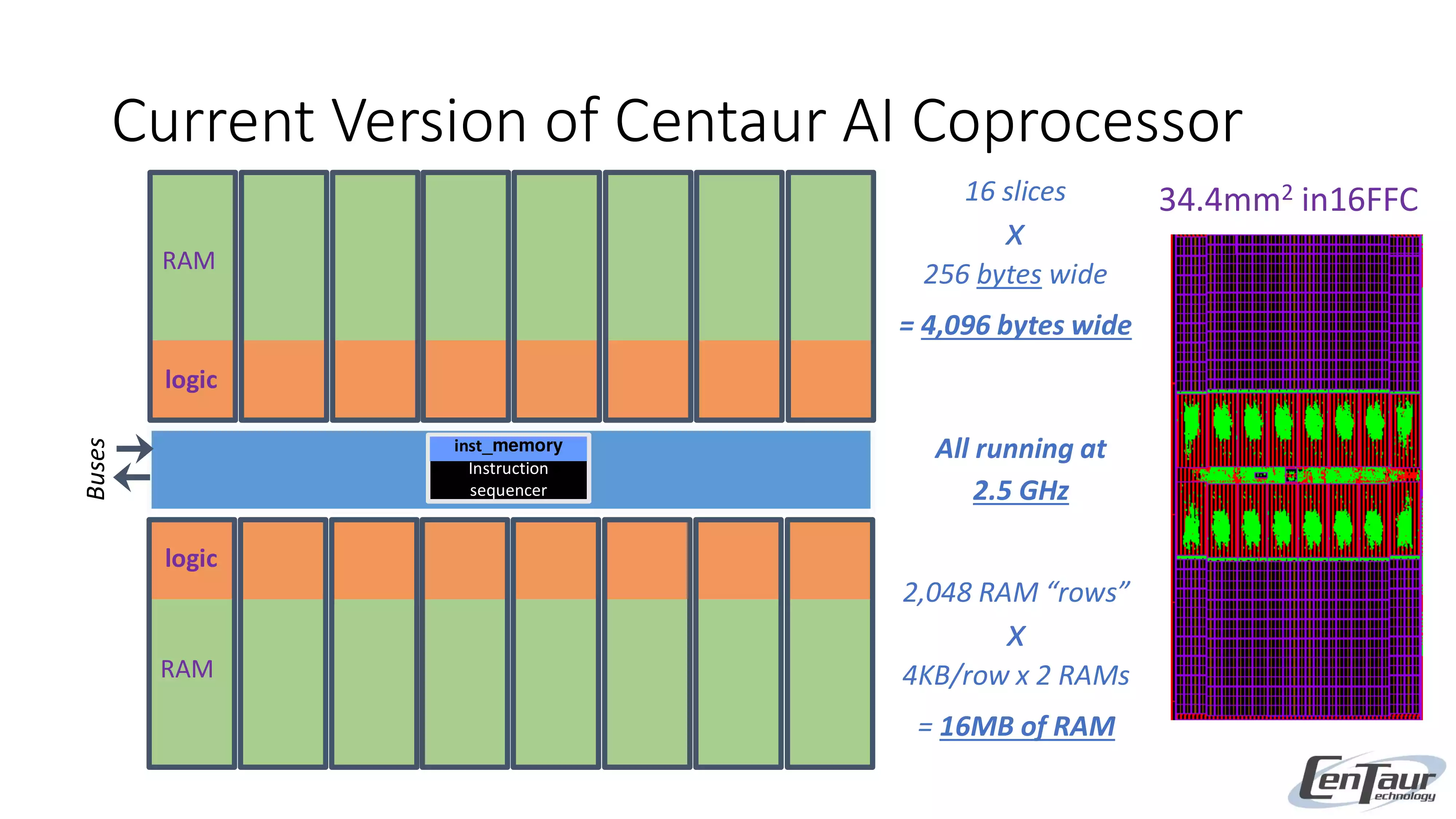
Current Version of Centaur AI Coprocessor
出典: MPR Article Template - MPR_19_12_02_Centaur_Adds_AI_to_Server_Processor.pdf
学習(トレーニング)は行わず、推論専用のアクセラレータ。
Ncore部のダイサイズはTSMC 16FFCプロセスで34.4mm2、
x86 CPU 8-Coreクラスターのおおよそ半分のサイズであり、Ncoreの約2/3は16MB SRAMが占める。
Computer unitは16スライスに分割されており、これによって設計をシンプルにしている。
緑色の部分はData Unit内の密集した金属配線を示し、この配線は主にデータの再配置するため。
そして16スライスの中央にある横長の部分に、Instruction UnitとRing Interfaceが含まれる。
クロックはx86コアと同じ2.5GHzであり、Ncore有効時にクロックが下がることはないとのこと。
ハードウェアレベルのコンテキストスイッチと仮想機能は持たず、シングルスレッドでの実行となる。
ソフトウェアベースでの仮想機能サポートは予定されているらしい。
x86コアはWindowsを動作させられるが、Ncoreのためのソフトウェアは現在Linux向けに開発されているとのこと。
こちらもWindows等の主流のOSで実行可能にする予定はあるらしい。
Ncore block diagram
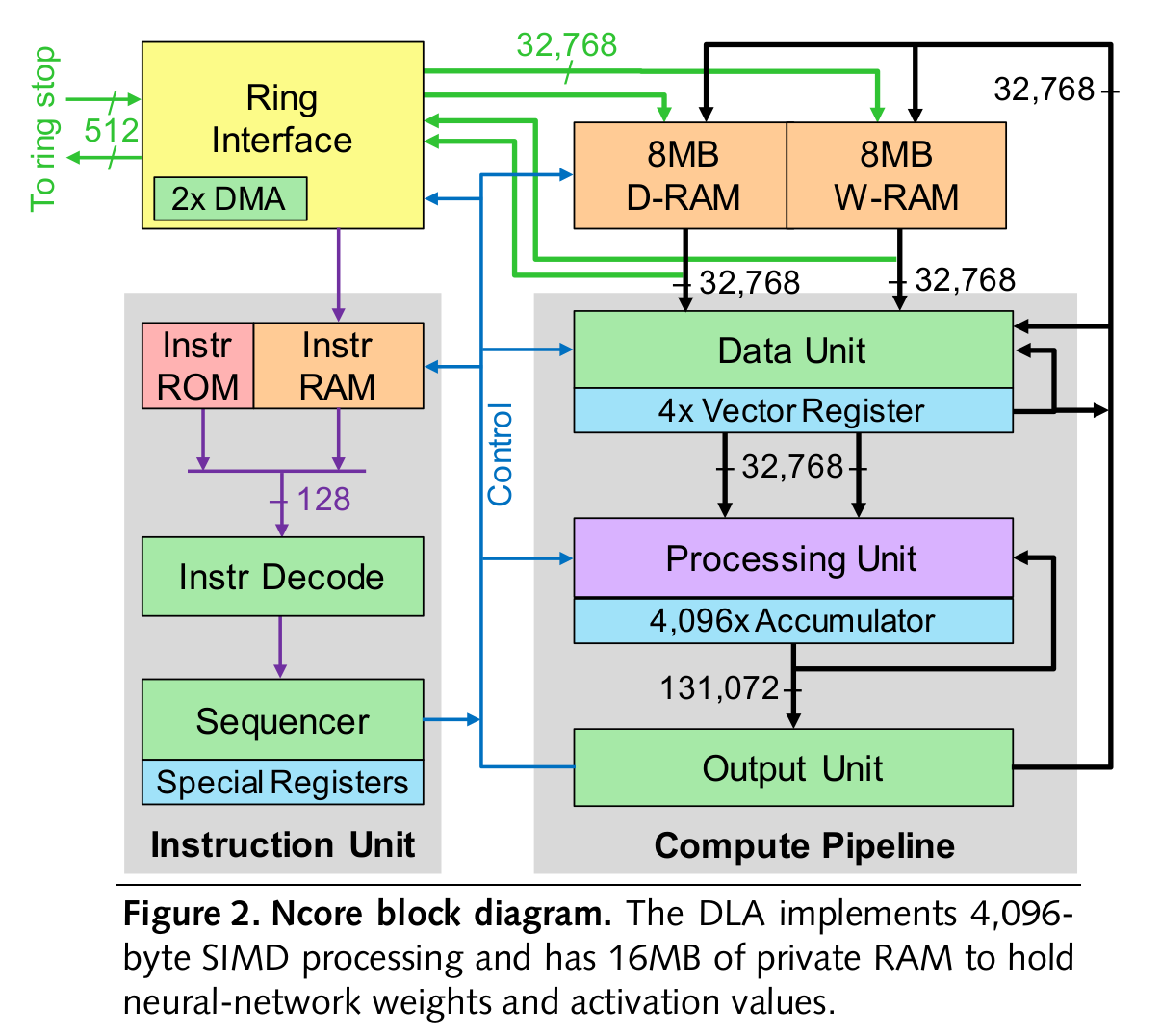
Ncore block diagram
出典: Centaur’s x86 SoC with AI Coprocessor Technology - PRSlides_1118_Release.pdf
SRAMは内部で2つに分かれており(D-RAMとW-RAM、DはData、WはWeightの意だろうか?)、それぞれSIMD幅に合わせて32,768-bit/cycleで接続されており、帯域は10TB/s、合計で20TB/sとなる。
どちらもECCに対応。
リングインターフェイスからData Unitへの書き込みを割り込ませることも可能だが、その間D-RAM/W-RAMからの書き込みは中断され、またそれら32,768-bitの接続に対し、リングインターフェイスは512-bitと狭く、十分にデータを供給するには64サイクルも必要とするため、割り込みが行なわれることは稀であるらしい。
INT8に最適化されており、INT16、Bfloat16の精度でも演算できるが、INT8は毎サイクル行なえるのに対し、INT16、Bfloat16では3サイクルかかり、スループットが落ちてしまう。
積和演算では、32-bit (INT32 or FP32) に飽和演算を行なう。
I/O
DDR4-3200 4-Channel ECCに対応し、ピークメモリ帯域は102 GB/sとなる。
PCIe Gen3 44-Laneを有し、サーバーにおいて標準的なサウスブリッジ機能(レガシーI/O)も内蔵されているため、統合されたソリューションを作成可能としている……が、
Redditのスレッドにおける回答では、USBとSATAは外部チップセットを必要とし、またグラフィック機能は内蔵されていない、とのこと。
(そこらへんはAspeedのBMCをボード側に搭載すればいい、ということだろうか)
またマルチソケット用のインターフェイスも存在し、2ソケットのシステムが可能だが、ソケット間接続のプロトコル、帯域等は不明。
ただ、それもリングバスで接続されていることを考えると、そう高くはなく、実効帯域も低めだろう。
参考までに記しておくと、Intel Xeon Scalableで双方向2x 10.4 GT/s@20レーン (104GT/s?)、(Cascade Lakeなら3リンクで156GT/s?)
AMD EPYC Romeで双方向4x 18GT/s@16レーン (288GT/s, 実帯域 202GB/s)。
- Intel® Xeon® Processor Scalable Family Technical Overview | Intel® Software
- AMDが最高性能のx86 CPUと謳う「AMD EPYC 7002」シリーズ - PC Watch
- [画像] 【後藤弘茂のWeekly海外ニュース】AMDが最高性能のx86 CPUと謳う「AMD EPYC 7002」シリーズ (25/28) - PC Watch
その他
製造プロセスはTSMC 16nm FinFet Compact(16FFC)。
ハイパフォーマンス向けの16FF+を低コストにしたのが16FFC (16FF Compact) であり、メインストリーム向けや低消費電力 (Ultra Low Power) 向けに位置付けされている。
- 10nmに見切りをつけ低コストの12FFCに注力 TSMC 半導体ロードマップ - ASCII.jp
- 16/12nm Technology - Taiwan Semiconductor Manufacturing Company Limited
- TSMC Symposium: New 16FFC and 28HPC+ Processes Target “Mainstream” Designers and Internet of Things (IoT) - Industry Insights - Cadence Blogs - Cadence Community
余談だが、Habanaの推論用アクセラレーター Goya、Cerebrasの学習用プロセッサー WSE (Wafer Scale Engine)もTSMC 16nmで製造されている。(16FFCかどうかは不明)
ユニットを増やし、並列に実行するのが効果的なディープラーニング用途ではコストの低さから人気なのかもしれない。
CPUのクロックは2.5GHzと、IntelやAMDのCPUと比べれば低いが、CPUの最高速度を制限することで、物理設計の最適化に費やす時間を大幅に短縮したとのこと。
Centaurは目標に、サーバークラスのシステムに1ドルあたりで最高のニューラルネットワーク性能を届けることを掲げている。
TSMC 16FFCプロセスを選び、物理設計の最適化に費やす時間を減らしたのもそのためだと考えられる。
まだCHAの具体的な価格とTDPは決まっていないが、I/O性能が近い Intel Xeon Silver 4209 ($417, Cascade Lake, 6ch DDR4-2400, PCIe Gen3 48-Lane)より高いピーク周波数で動作しつつ、少ない消費電力になることを 期待 しているとのこと。
そして価格も近くなるだろう、とも言っている。
そしてNcoreの、MLPerfで MobileNetとResNet-50 をモデルに計測した推論性能は、AVX-512VNNI命令を使用した$5,000のXeon Platinumとほぼ同じくらい強力であり、
先程挙げた、CHAと同等のXeon Silverよりも5倍高速と推定している。
Intelには推論用のアクセラレーター、NNP-Iがあり、Xeon Silverと組み合わせることができるが、当然システムにかかるコストは高価となり、(Intelはまだ価格を公表していないが$500~1,000になると見ているらしい)
また、NvidiaのT4といったカードを搭載しようとすると、追加で約$2,000のコストがかかる。
どちらも性能こそ高いが、システムのプロセッサーよりも高価であることがほとんどだ。
CHAならば外部DLA無しに、低いコストで優れた性能を得ることができ、
ソフトウェアもまだ最適化中の段階にあるため、製品が市場に出るまでに性能が向上することも考えられる。
そうなればCHAのアドバンテージはさらに広がるだろう。
感想とか
ここから先は完全に個人的な感想と推測。
今後の展開が気になる所。
微細化が進めばx86 CPUのアーキテクチャを拡張する余裕ができるだろうし、コアとバスが同じクロックで動作するCHAはクロック向上がそのまま全体の帯域に反映される。
micro-opキャッシュの追加はまずあるだろう。
Ncoreも専用SRAMを増やす、Ncoreのクラスタを追加するといった拡張が考えられるだろう。
SIMD幅をさらに増やすかは、今もソフトウェアの最適化で忙しいだろうに、その時にまた最適化の手間がかかることを考えるとまだやらないのではないかと思う。
メモリ、I/Oも、7nmで製造されるZhaoxin 7-SeriesがDDR5、PCIe Gen4に対応することを考えれば、次世代CHAでの対応も期待できる。
16FFCのままでx86 CPU、メモリーコントローラー、I/Oをスケールダウンさせ、より小型な推論用エッジサーバー向けのSoCがあっても面白そうだが、そのターゲット層だと絶対的な消費電力が課題となるのかもしれない。
x86 CPUでmicro-opキャッシュも持たないCNSアーキテクチャは消費電力の点で、他のARM+コプロセッサーの構成を取る製品より劣るはずだ。
色んなことを期待しつつ、今後も情報を追っていきたい。