自作の AMD GPU モニタリングツールを、プロセスごとの fdinfo から取得できる AMD GPU の使用量の取得に対応させた、そのメモ。
自分が取った方法の解説的なものも書いておくが、自分がそれにしか気付けなかっただけでもっと効率の良い方法があるかもしれない。
fdinfo
まず対応している DRM (Direct Rendering Manager) ドライバーであれば、fdinfo にドライバー内で計測した情報を出力し、ユーザースペースで動作するモニタリングツールがその情報を利用可能なようにしている。
fdinfo は /proc/<pid>/fdinfo/ 下にあり、ファイル名は対応した fd (File descriptor) になっている。
ドライバー側は現在公開されている Linux Kernel のバージョンだと、AMDGPU ドライバーが v5.15.xxx、Intel GPU (i915) ドライバーは v6.1.xxx で対応している。
fdinfo からの GPU 使用量の取得に対応したモニタリングツールには intel_gpu_top と nvtop がある。
intel_gpu_top は名前の通り Intel GPU のみの対応だが、PMU (Performance Monitoring Unit, Performance Counter) からの読み取りにも対応しており、消費電力やメモリ帯域といった情報も表示可能。
nvtop は逆に NVIDIA GPU 以外に AMD GPU と Intel GPU にも対応している。nvtop では fdinfo から取得可能な情報の他に、hwmon や sysfs から取得可能な GPU の各種センサー情報やクロック、PCIe の情報も表示する。
- man/intel_gpu_top.rst · master · drm / igt-gpu-tools · GitLab
- Syllo/nvtop: GPUs process monitoring for AMD, Intel and NVIDIA
fdinfo に出力される情報は基本的な部分以外ドライバーごとで異なる。
AMDGPU ドライバーは VRAM (drm-memory-vram)、GTT (drm-memory-gtt)、CPU がアクセス可能な VRAM (drm-memory-cpu) の使用量と、各 Hardware IP (GFX, COMPUTE, DMA, UVD, VCE, UVD_ENC, VCN_DEC, VCN_ENC, VCN_JPEG) の使用時間 (ns) を出力する。
/* * ****************************************************************** * For text output format description please see drm-usage-stats.rst! * ****************************************************************** */ seq_printf(m, "pasid:\t%u\n", fpriv->vm.pasid); seq_printf(m, "drm-driver:\t%s\n", file->minor->dev->driver->name); seq_printf(m, "drm-pdev:\t%04x:%02x:%02x.%d\n", domain, bus, dev, fn); seq_printf(m, "drm-client-id:\t%Lu\n", vm->immediate.fence_context); seq_printf(m, "drm-memory-vram:\t%llu KiB\n", vram_mem/1024UL); seq_printf(m, "drm-memory-gtt: \t%llu KiB\n", gtt_mem/1024UL); seq_printf(m, "drm-memory-cpu: \t%llu KiB\n", cpu_mem/1024UL); for (hw_ip = 0; hw_ip < AMDGPU_HW_IP_NUM; ++hw_ip) { if (!usage[hw_ip]) continue; seq_printf(m, "drm-engine-%s:\t%Ld ns\n", amdgpu_ip_name[hw_ip], ktime_to_ns(usage[hw_ip])); }
Intel GPU (i915) ドライバーは各エンジン (RENDER, COPY, VIDEO, VIDEO_ENHANCE, COMPUTE) の使用時間 (drm-engine-<engine-name>) とエンジン数 (drm-engine-capacity-<engine-name>) を出力する。
各 VRAM 使用量はそのまま使えるが、各 Hardware IP の使用時間は合計であるため、使用率を出すには前回取得した結果と更新間隔が必要になる。
fdinfo から取得できる情報は一度置いて、fdinfo の読み取りまでには稼働してる全プロセスから GPU を使用しているプロセスを抽出し、さらにそのプロセスから GPU に関連付けられた fd の抽出が必要となる。
まずプロセスの一覧だが、必要なのは PID なので単に /proc/ 直下にある数字のみディレクトリ名を PID として使えばいい。Rust であれば procfs クレートの procfs::process::all_processes を使う方法もある。
次に fd の抽出だが、/proc/<pid>/fd/ 下にあるファイルはそのプロセスで開いているファイルへのシンボリックリンクになっている。そして DRM ドライバーの場合、リンク先が /dev/dri/renderD128 (以降 /dev/dri/renderD129 ...) となっているため、そこで判定、抽出することができる。
Rust では std::fs::read_link でリンク先のパスを取得できる。
fdinfo の drm-pdev が GPU の PCI バス情報 (domain:bus:dev:function) になっているため、抽出せずに /proc/<pid>/fdinfo/ 下にあるファイルをすべて読み、drm-pdev で判定する方法もある。
前者は毎回すべての fdinfo を読む必要がなく、またデバイスハンドルの初期化に用いるパスをそのまま判定に用いることができたため、自分は前者を選んだ。
後は fdinfo をパースし、各使用量を加算、合計をそのプロセスの GPU 使用量とすればいい。
ただ、fd は異なってもドライバー内でのコンテキストは同じ場合があるため、drm-client-id が重複していないか確認する必要がある。Rust であれば HashSet を使えばいい。
使用率の計算には、前述したように前回の結果と更新間隔の情報が必要となる。
自分の場合は、PID をキーにした HashMap に前回の結果を格納するようにしている。
それとプロセス名も表示したい場合は /proc/<pid>/comm から取得できる。
すべての /proc/<pid>/ を見て、PID とそのプロセスの GPU に関連付けられている fd、オプションでプロセス名、それらをまとめたインデックスを毎回生成するのはコストが高いと思われる。
そのためインデックスを Arc<Mutex<T>> で包み、インデックスからプロセスごとの使用量と使用率を計算して表示を更新するスレッドとは別にインデックスを更新するスレッドを作るようにした。
インデックスの更新用スレッドは lock()、表示更新用のスレッドは try_lock() を用いてロックする。
インデックスの更新間隔は表示の更新よりも遅くしてあり、表示が 1秒か 0.1秒間隔なのに対し、インデックスは今の所 5秒間隔で更新するようにしている。
試した限りでは、更新間隔を縮めても表示更新用のスレッドがロックの確保に失敗することはなく、また失敗しても使用率の計算に使う更新間隔に 1周分加算しておけばいいだけなので、5秒ではなく 2秒とか 3秒でもいいかも。
ソート機能も実装したが、一旦 PID、プロセス名、各使用率をまとめた構造体の Vec を作るようにして、それからソートしたい種類に応じて sort_by を実行するようにするだけで良かった。
match (sort, reverse) { (FdInfoSortType::PID, false) => b.pid.cmp(&a.pid), (FdInfoSortType::PID, true) => a.pid.cmp(&b.pid), (FdInfoSortType::VRAM, false) => b.usage.vram_usage.cmp(&a.usage.vram_usage), (FdInfoSortType::VRAM, true) => a.usage.vram_usage.cmp(&b.usage.vram_usage), (FdInfoSortType::GFX, false) => b.usage.gfx.cmp(&a.usage.gfx), (FdInfoSortType::GFX, true) => a.usage.gfx.cmp(&b.usage.gfx), (FdInfoSortType::MediaEngine, false) => (b.usage.dec + b.usage.enc + b.usage.uvd_enc) .cmp(&(a.usage.dec + a.usage.enc + a.usage.uvd_enc)), (FdInfoSortType::MediaEngine, true) => (a.usage.dec + a.usage.enc + a.usage.uvd_enc) .cmp(&(b.usage.dec + b.usage.enc + b.usage.uvd_enc)), }
以下は自環境での実行結果。
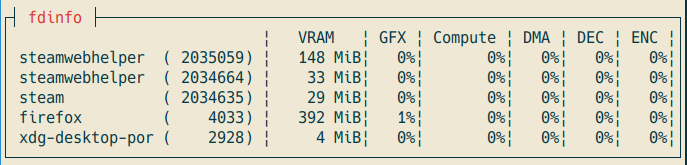
fdinfo
GPU Metrics
AMDGPU ドライバーは対応している APU/dGPU であれば sysfs に GPU Metrics (ファイル名は gpu_metrics) を出力する。
AMDGPU ドライバーのコードを見るに、dGPU は Vega12 とそれ以降、APU は Renoir から GPU Metrics に対応している。
GPU Metrics には温度、クロック、エンジンの使用状況、消費電力、スロットルの状態といった情報が含まれている。APU であれば CPU コアごとの温度、クロック、消費電力、L3 キャッシュの温度とクロックも含まれる。
モニタリングツールに表示させておきたい情報が揃っているが、gpu_metrics ファイルはフォーマットされた文字列ではなくバイナリデータとなっているため少し扱いづらい。
/** * DOC: gpu_metrics * * The amdgpu driver provides a sysfs API for retrieving current gpu * metrics data. The file gpu_metrics is used for this. Reading the * file will dump all the current gpu metrics data. * * These data include temperature, frequency, engines utilization, * power consume, throttler status, fan speed and cpu core statistics( * available for APU only). That's it will give a snapshot of all sensors * at the same time. */
GPU Metrics の構造体定義が drivers/gpu/drm/amd/include/kgd_pp_interface.h にあり、gpu_metrics_v1_{0,1,2,3} が dGPU 向け、gpu_metrics_v2_{0,1,2,3} が APU 向けとなる。
ただ gpu_metrics_v1_x と gpu_metrics_v2_x で異なり、さらに gpu_metrics_v1_x だとそれぞれで構造体の中身が異なるため、プログラム側でそのまま使うのは難しい。
取得する際も、gpu_metrics の最初 4バイトがヘッダとなっているため、まずそこでバージョンを確認する必要がある。
struct metrics_table_header { uint16_t structure_size; uint8_t format_revision; uint8_t content_revision; };
gpu_metrics_v1_x と gpu_metrics_v2_x の内容すべてを網羅した構造体を別に定義し、バージョンを見てから変換する方法も考えられるが、変換部分をバージョン分書く必要があり面倒。
一部の値だけを変換する方法ならば少しは楽になるが、当然抜け落ちて使えなくなる値が出てくる。
そこで以下のような enum を定義し、gpu_metrics_v1_x と gpu_metrics_v2_x それぞれにトレイトを実装する方法を取った。
メソッドが返す値はすべて Option<T> であり、その構造体が持っていない値の場合は None を返す。
トレイトを以下の GpuMetics にも実装すれば、構造体のバージョン違いを意識することなく扱うことが可能となる。
バイナリデータから構造体への変換には、MaybeUninit<T> と ptr::copy_nonoverlapping を使うことで可能。
pub enum GpuMetrics { Unknown, V1_0(gpu_metrics_v1_0), V1_1(gpu_metrics_v1_1), V1_2(gpu_metrics_v1_2), V1_3(gpu_metrics_v1_3), V2_0(gpu_metrics_v2_0), V2_1(gpu_metrics_v2_1), V2_2(gpu_metrics_v2_2), V2_3(gpu_metrics_v2_3), }
トレイトの実装に慣れないマクロを使いまくったが、結果的にはシンプルで維持も楽になったため良かった。
以下は Cezanne /Green Sardine APU での実行結果。GPU Metrics のバージョンは gpu_metrics_v2_2 となる。
試した限りでは、average_gfx_power に Cezanne /Green Sardine APU は対応しておらず、0xFFFF (65535) で固定だったため、そうした値の場合は表示しないようにしている。
gpu_metrics_v2_2 は現状 Renoir APU 系統と Cyan Skilfish/Skillfish APU と SMU バージョンが古い VanGogh APU で使われており、Renoir APU 系統は average_gfx_power に対応していないようだった。
